更新时间:2024-12-17 gmt 08:00
端到端运维modelarts standard推理服务方案-九游平台
modelarts推理服务的端到端运维覆盖了算法开发、服务运维和业务运行的整个ai流程。
方案概述
推理服务的端到端运维流程
- 算法开发阶段,先将业务ai数据存放到对象存储服务(obs)中,接着通过modelarts数据管理进行标注和版本管理,然后通过训练获得ai模型结果,最后通过开发环境构建模型镜像。
- 服务运维阶段,先利用镜像构建模型,接着部署模型为在线服务,然后可在云监控服务(ces)中获得modelarts推理在线服务的监控数据,最后可配置告警规则实现实时告警通知。
- 业务运行阶段,先将业务系统对接在线服务请求,然后进行业务逻辑处理和监控设置。
图1 推理服务的端到端运维流程图
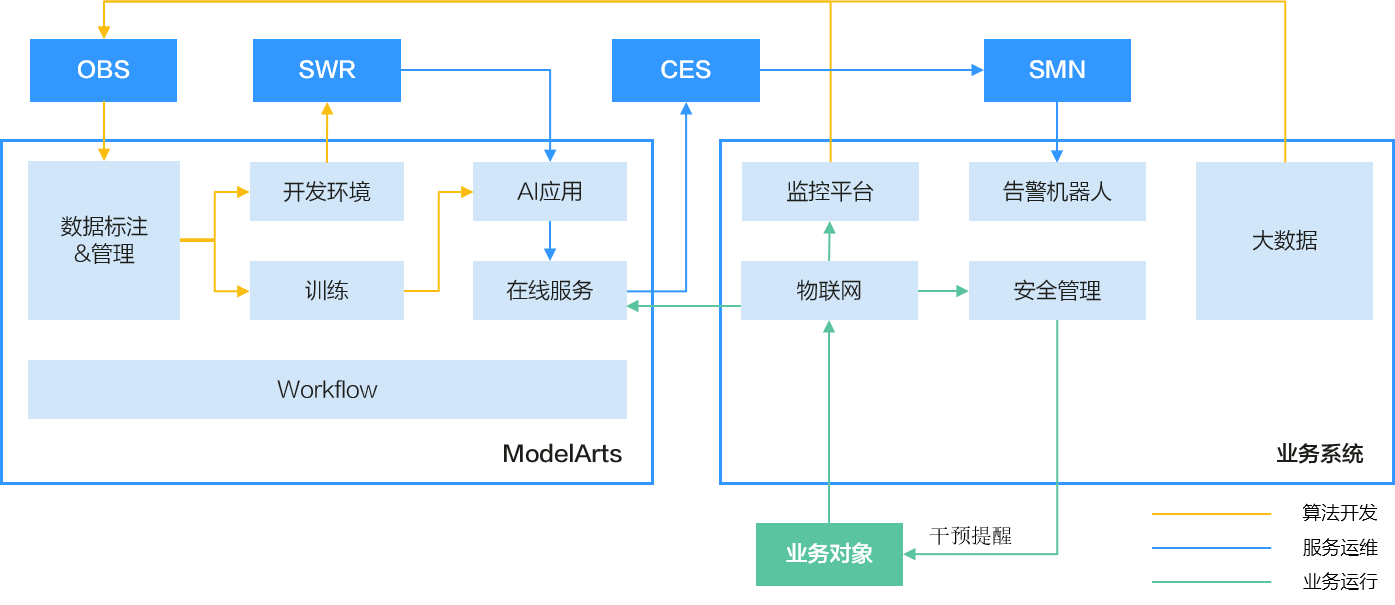
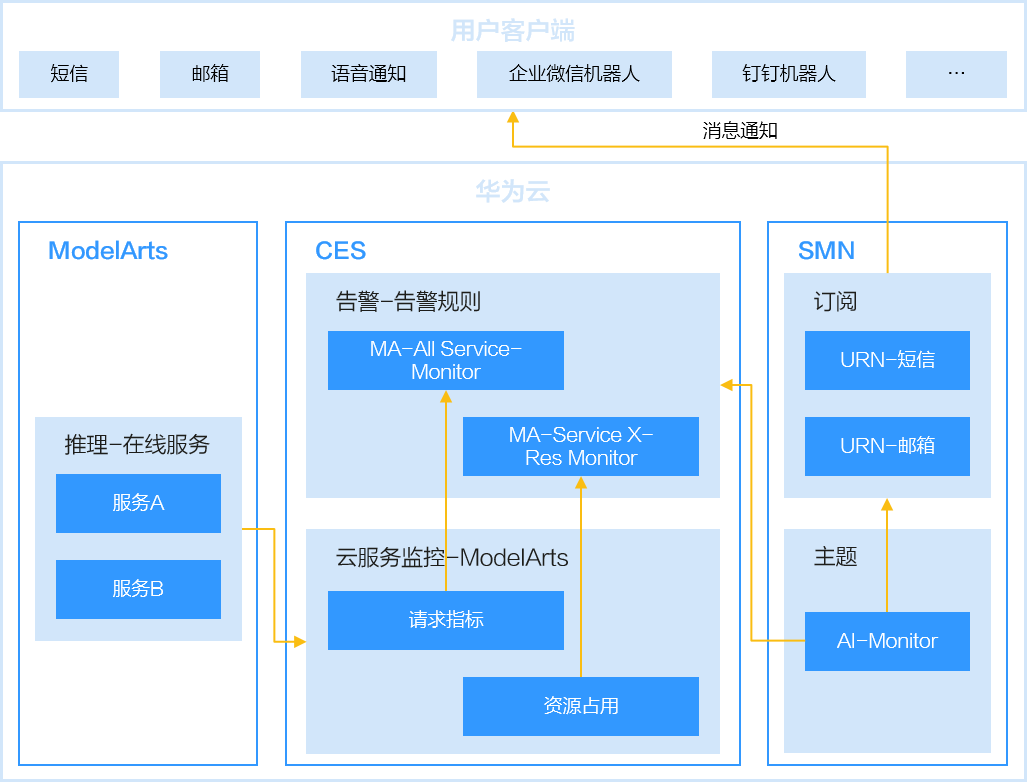
整个运维过程会对服务请求失败和资源占用过高的场景进行监控,当超过阈值时发送告警通知。
图2 监控告警流程图
方案优势
通过端到端的服务运维配置,可方便地查看业务运行高低峰情况,并能够实时感知在线服务的健康状态。
约束限制
端到端服务运维只支持在线服务,因为推理的批量服务和边缘服务无ces监控数据,不支持完整的端到端服务运维设置。
实施步骤
以出行场景的司乘安全算法为例,介绍使用modelarts进行流程化服务部署和更新、自动化服务运维和监控的实现步骤。
图3 司乘安全算法
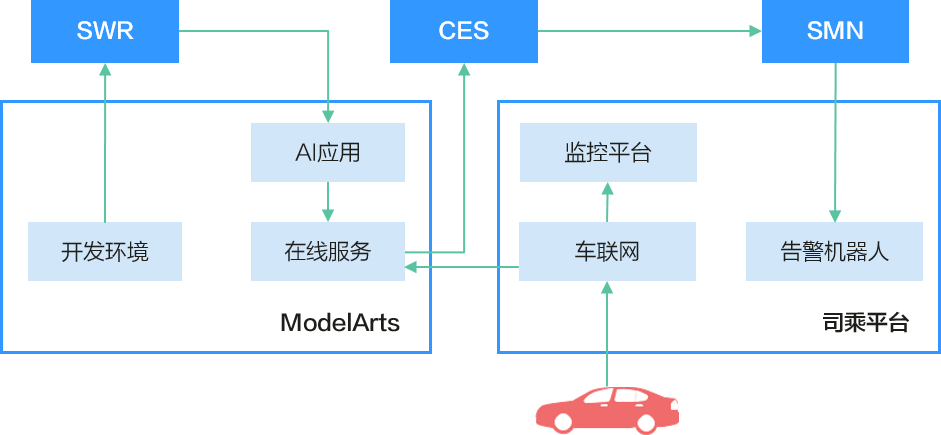
- 将用户本地开发完成的模型,使用自定义镜像构建成modelarts standard推理平台可以用的模型。具体操作请参考从0-1制作自定义镜像并创建模型。
- 在modelarts管理控制台,使用创建好的模型部署为在线服务。
- 登录云监控服务ces管理控制台,设置modelarts服务的告警规则并配置主题订阅方式发送通知。具体操作请参考。
当配置完成后,在左侧导航栏选择即可查看在线服务的请求情况和资源占用情况,如下图所示。
图4 查看服务的监控指标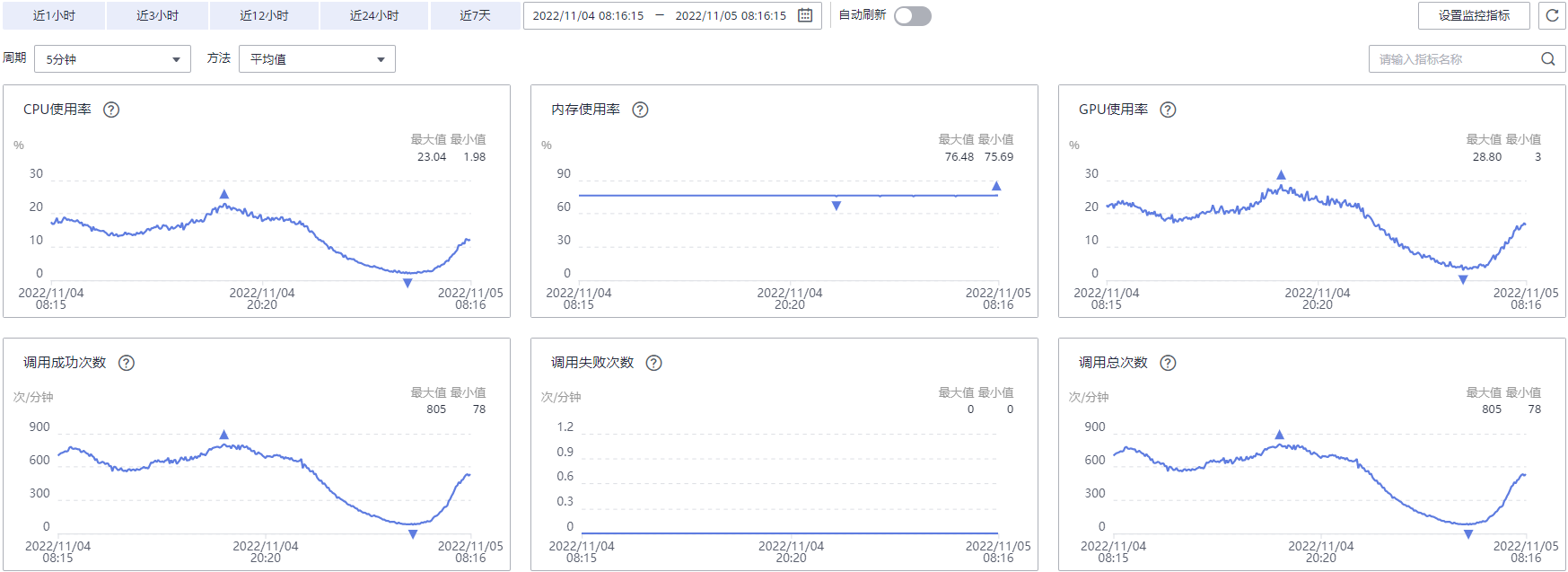
当监控信息触发告警时,主题订阅对象将会收到消息通知。
图5 告警消息通知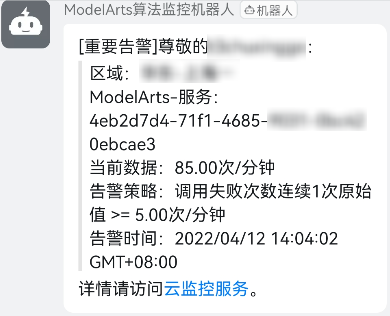
父主题: standard推理部署
相关文档
意见反馈
文档内容是否对您有帮助?
提交成功!非常感谢您的反馈,我们会继续努力做到更好!
您可在查看反馈及问题处理状态。
系统繁忙,请稍后重试
如您有其它疑问,您也可以通过华为云社区问答频道来与我们联系探讨




