使用modelarts vscode插件调试训练resnet50图像分类模型-九游平台
应用场景
notebook等线上开发工具工程化开发体验不如ide,但是本地开发服务器等资源有限,运行和调试环境大多使用团队公共搭建的cpu或gpu服务器,并且是多人共用,这带来一定的环境搭建和维护成本。因此使用本地ide 远程notebook结合的方式,可以同时享受ide工程化开发和云上资源的即开即用,优势互补,满足开发者需求。
vs code在python项目开发中提供了优秀的代码编辑、调试、远程连接和同步能力,在开发者中广受欢迎。本文以ascend model zoo为例,介绍如何通过vs code插件及modelarts notebook进行云端数据调试及模型开发。
方案优势
云端开发调试优势:
- 环境保持一致
- 配置一键完成
- 代码远程调试
- 资源按需使用
准备工作
- 下载vs code ide,下载路径:。根据不同的操作系统选择不同的安装包。
- 创建notebook实例。
- ,单击左侧导航“开发环境 > notebook”,然后单击“创建”。
镜像选择“mindspore1.7.0-cann5.1.0-py3.7-euler2.8.3”,类型选择“ascend”,并打开“ssh远程开发”开关,密钥对选择已有的或单击“立即创建”。
- notebook创建后,“状态”为“运行中”。单击“操作”列的“打开”,进入jupyterlab,然后参考下图打开terminal。
图1 打开terminal
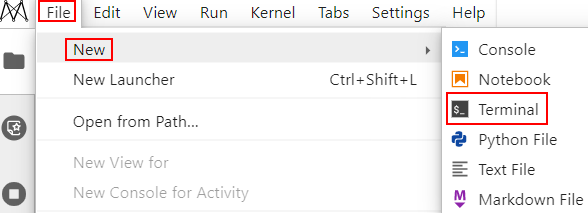
- ,单击左侧导航“开发环境 > notebook”,然后单击“创建”。
- 下载项目代码。
在terminal执行如下命令下载项目代码。本例中,以图像分类模型resnet50模型为例。下载后的文件如图2所示,代码所在路径为“./models/official/cv/resnet/”。
# 下载代码 git clone https://gitee.com/mindspore/models.git -b v1.5.0
图2 下载后的模型包文件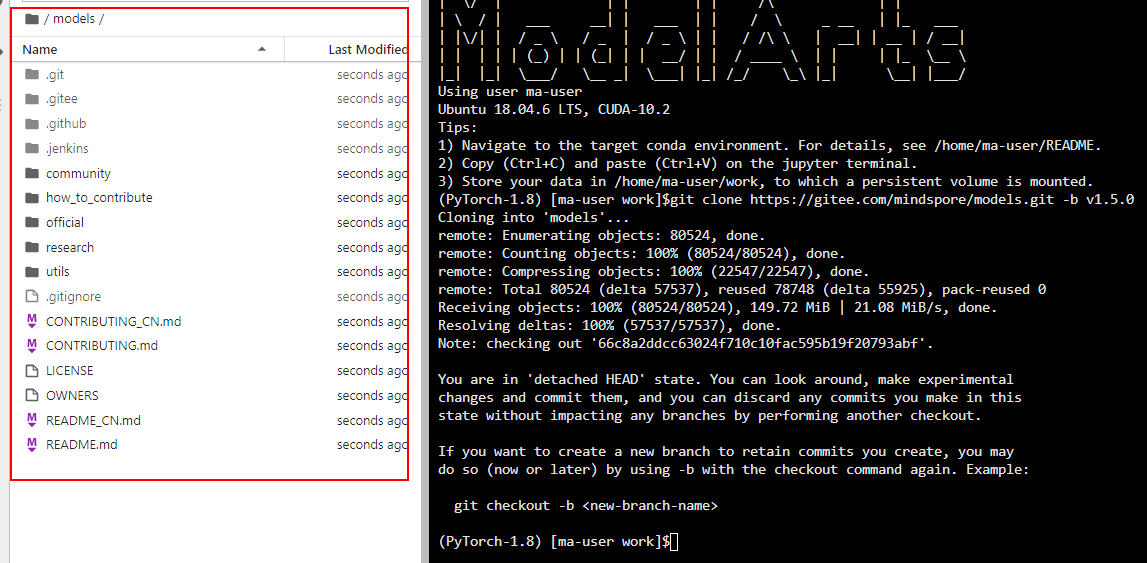
- 下载花卉识别数据集。
本样例使用的数据集为类别数为五类的花卉识别数据集。
在terminal里执行如下命令下载并解压数据集,将数据集保存在“./models/dataset/flower_photos”文件夹。cd models mkdir dataset cd dataset wget tar zxvf flower_photos.tgz
步骤1:通过vs code插件连接云端notebook
通过vs code插件连接准备工作里创建的云端notebook,详细操作请参考vs code一键连接notebook。
步骤2:安装python插件以及配置入参
- 打开vs code工具,单击“extensions”,搜索python,然后单击“install”。
图3 安装python
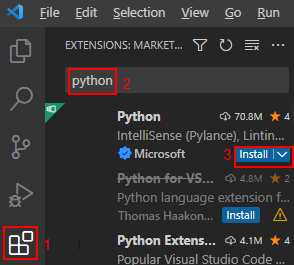
- 输入ctrl shirt p,搜索“python:select interpreter”,选择python解释器。
图4 选择python解释器
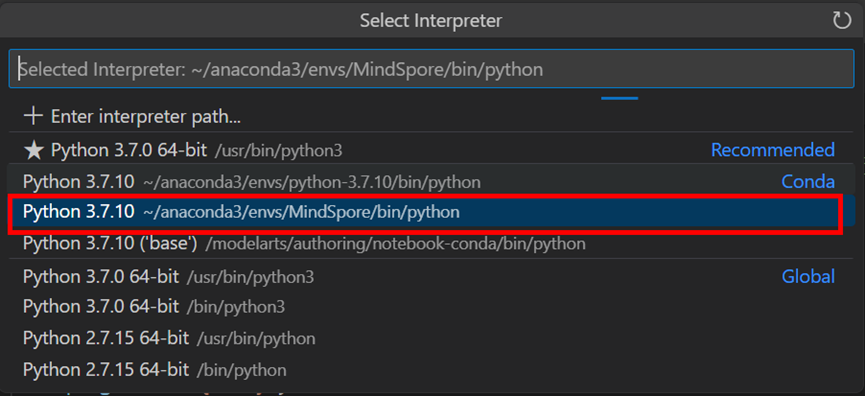
- 单击 选择python > python file,填入如下代码。
如果文件已创建,单击,填入如下代码。
# 根据readme说明文档,配置的parameter入参如下,其中device_target="cpu"表示cpu环境运行,device_target="ascend"表示在ascend环境运行
"configurations": [ { "name": "python: django debug single test", "type": "python", "request": "launch", "program": "${file}", "args":[ "--net_name", "resnet50", "--dataset", "imagenet2012", "--data_path", "/home/ma-user/work/models/dataset/flower_photos/", "--class_num", "5", "--config_path", "/home/ma-user/work/models/official/cv/resnet/config/resnet50_imagenet2012_config.yaml", "--epoch_size", "1", "--device_target","ascend" ] } ]
步骤3:在vs code中远程调试代码
- 参考准备工作上传本地代码和数据至云端notebook。
- 云端notebook安装依赖。
在本地ide中打开,执行如下命令。
pip install -r /home/ma-user/work/models/official/cv/resnet/requirements.txt
图5 执行命令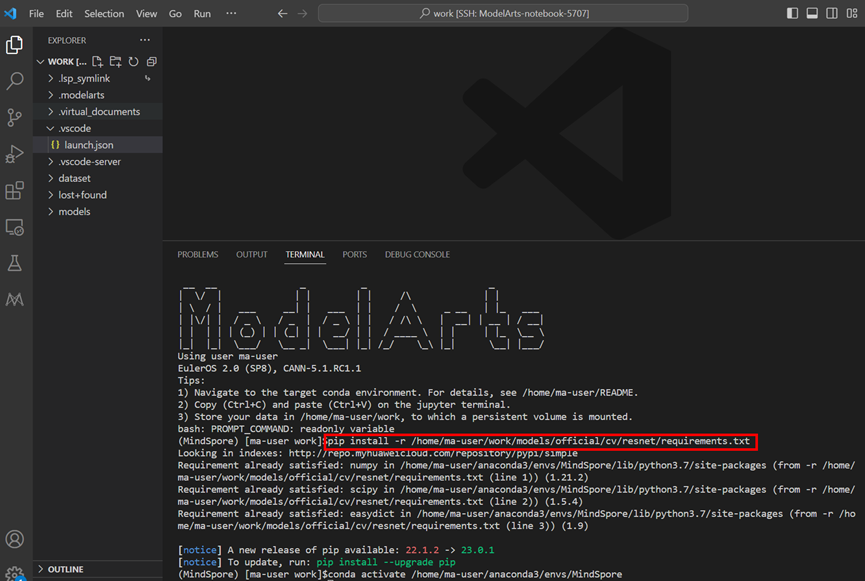
- 云端调试与运行。
- 打开训练文件。文件所在路径为“/home/ma-user/work/models/official/cv/resnet/train.py”
- 代码调测:在需要调测点打断点,然后单击。
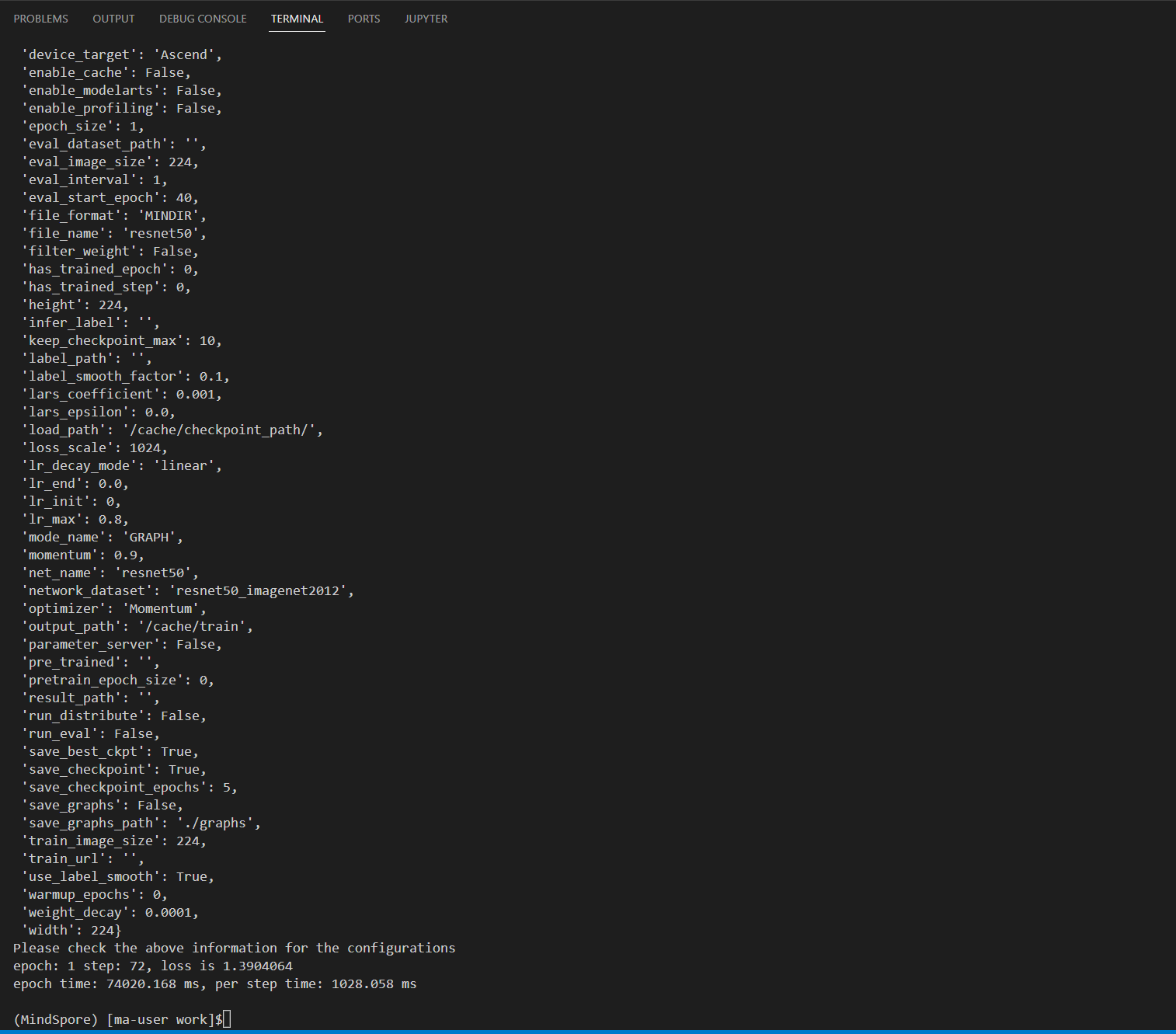
- 代码运行:单击,运行结果如下:
图6 代码运行结果
步骤4:保存开发环境镜像
完成notebook调测后,此时的notebook已经包含了模型训练所有的依赖环境,因此可以将已经调测完成的开发环境保存成一个镜像。
- 方式一:保存镜像需要指定镜像名称、镜像标签、swr服务的组织等信息,保存镜像需要等待几分钟时间,期间不能对notebook有额外操作。
swr服务的组织可以在swr服务中进行创建,也可以使用sdk创建默认的swr组织,默认最多只能创建5个组织。
- 在“/home/ma-user/work/models/official/cv/resnet/”下创建save_image.py,
- 复制代码至save_image.py,
- 运行save_image.py,进行保存镜像。
save_image.py代码如下:
# save_image.py # 导入modelarts sdk的依赖,并初始化session,此处的ak、sk、project_id、region_name请替换成用户自己的信息 from modelarts.session import session # 认证用的ak和sk硬编码到代码中或者明文存储都有很大的安全风险,建议在配置文件或者环境变量中密文存放,使用时解密,确保安全; # 本示例以ak和sk保存在环境变量中来实现身份验证为例,运行本示例前请先在本地环境中设置环境变量huaweicloud_sdk_ak和huaweicloud_sdk_sk。 __ak = os.environ["huaweicloud_sdk_ak"] __sk = os.environ["huaweicloud_sdk_sk"] # 如果进行了加密还需要进行解密操作 session = session(access_key=__ak,secret_key=__sk, project_id='***', region_name='***') # 保存notebook镜像 from modelarts.image_mgmt import imagesave from modelarts.service import swrmanagement # 创建一个镜像组织。如果组织数量已超过阈值,则会报错“namespace is invalid”,需要删除一个组织或手动指定一个已有的组织信息(使用image_organization = “your-swr-namespace-name”指定) image_organization = swrmanagement(session).get_default_namespace() # image_organization = “your-swr-namespace-name” print("default image_organization:", image_organization) image_name = "mindspore-image-models-image" #@param {type:"string"} image_tag = "1.0.0" #@param {type:"string"} image_save = imagesave(session=session, name=image_name, tag=image_tag, organization=image_organization) image_save.save() - 方式二:在modelarts控制台单击“保存镜像”。
在notebook列表中,对于要保存的notebook实例,单击右侧“操作”列的“更多 > 保存镜像”,进入“保存镜像”页面,设置组织、镜像名称、镜像版本和描述信息后单击“确认”保存镜像。此时notebook会冻结,需要等待几分钟。详细操作请参考保存notebook镜像环境。
图7 保存镜像
查看所保存的镜像
保存后的镜像可以在modelarts控制台“镜像管理”页面查看到该镜像详情。单击镜像的名称,进入镜像详情页,可以查看镜像版本/id,状态,资源类型,镜像大小,swr地址等。
步骤5:使用sdk提交训练作业
本地调测完成后可以提交训练作业。因为数据在notebook中,设置inputdata中“is_local_source”的参数为“true”,会自动将本地数据同步上传到obs中。
步骤如下:
- 在“/home/ma-user/work/models/official/cv/resnet/”下创建train_notebook.py,
- 复制代码至train_notebook.py,
- 运行train_notebook.py,进行训练作业提交。
# train_notebook.py
# 导入modelarts sdk的依赖,并初始化session,此处的ak、sk、project_id、region_name请替换成用户自己的信息
from modelarts.train_params import trainingfiles
from modelarts.train_params import outputdata
from modelarts.train_params import inputdata
from modelarts.estimatorv2 import estimator
from modelarts.session import session
# 认证用的ak和sk硬编码到代码中或者明文存储都有很大的安全风险,建议在配置文件或者环境变量中密文存放,使用时解密,确保安全;
# 本示例以ak和sk保存在环境变量中来实现身份验证为例,运行本示例前请先在本地环境中设置环境变量huaweicloud_sdk_ak和huaweicloud_sdk_sk。
__ak = os.environ["huaweicloud_sdk_ak"]
__sk = os.environ["huaweicloud_sdk_sk"]
# 如果进行了加密还需要进行解密操作
session = session(access_key=__ak,secret_key=__sk, project_id='***', region_name='***')
# 样例中为了方便默认创建一个obs桶,推荐将调测所需要传输的文件统一放到`${default_bucket}/intermidiate`目录下,也可以按照注释代码自行指定
obs_bucket = session.obs.get_default_bucket()
print("default bucket name: ", obs_bucket)
default_obs_dir = f"{obs_bucket}/intermidiate"
#default_obs_dir = "obs://your-bucket-name/folder-name"
# 本地的工程代码文件夹路径
code_dir_local = "/home/ma-user/work/models/official/cv/resnet/" #@param {type:"string"}
# 代码的启动文件名称
boot_file = "train.py" #@param {type:"string"}
train_file = trainingfiles(code_dir=code_dir_local, boot_file=boot_file)
# 本地数据集路径
local_data_path = "/home/ma-user/work/models/dataset/flower_photos" #@param {type:"string"}
# 模型输出保存路径
output_local = "/home/ma-user/work/models/official/cv/resnet/output" #@param {type:"string"}
# 模拟训练过程中模型输出回传至指定obs的路径,需要以"/"结尾
obs_output_path = f"{default_obs_dir}/mindspore_model/output/"
# 指定一个obs路径用于存储输出结果
output = [outputdata(local_path=output_local, obs_path=obs_output_path, name="output")]
# 模拟训练过程中模训练日志回传至指定obs的路径,需要以"/"结尾
log_obs_path = f"{default_obs_dir}/mindspore_model/logs/"
# 训练所需的代码路径,代码会自动从本地上传至obs
code_obs_path = f"{default_obs_dir}/mindspore_model/"
data_obs_path = f"{default_obs_dir}/dataset/flower_photos/"
# sdk会将代码自动上传至obs,并同步到训练环境
train_file = trainingfiles(code_dir=code_dir_local, boot_file=boot_file, obs_path=code_obs_path)
# 指定obs中的数据集路径,会自动将local_path数据上传至obs_path,用户可以在代码中通过 --data_url接收这个数据集路径
input_data = inputdata(local_path=local_data_path, obs_path=data_obs_path, is_local_source=true, name="data_url")
from modelarts.service import swrmanagement
image_organization = swrmanagement(session).get_default_namespace()
# image_organization = "your-swr-namespace-name"
print("default image_organization:", image_organization)
image_name = "mindspore-image-models-image" #@param {type:"string"}
image_tag = "1.0.0" #@param {type:"string"}
import os
env_name=os.getenv('env_name')
# 启动训练作业:使用user_command(shell命令)方式启动训练作业
# 注意:训练启动默认的工作路径为"/home/ma-user/modelarts/user-job-dir",而代码上传路径为"./resnet/${code_dir}"下
# --enable_modelarts=true 该代码仓已适配modelarts
estimator = estimator(session=session,
training_files=train_file,
outputs=output,
user_image_url=f"{image_organization}/{image_name}:{image_tag}", # 自定义镜像swr地址,由镜像仓库组织/镜像名称:镜像tag组成
user_command=f'cd /home/ma-user/modelarts/user-job-dir/ && /home/ma-user/anaconda3/envs/mindspore/bin/python ./resnet/train.py --net_name=resnet50 --dataset=imagenet2012 --enable_modelarts=true --class_num=5 --config_path=./resnet/config/resnet50_imagenet2012_config.yaml --epoch_size=10 --device_target="ascend" --enable_modelarts=true', # 执行训练命令
train_instance_type="modelarts.p3.large.public", # 虚拟资源规格,不同region的资源规格可能不同,请参考“estimator参数说明”表下的说明查询修改
train_instance_count=1, # 节点数,适用于多机分布式训练,默认是1
#pool_id='若指定专属池,替换为页面上查到的poolid',同时修改资源规格为专属池专用的虚拟子规格
log_url=log_obs_path
)
# job_name是可选参数,可不填随机生成工作名
job_instance = estimator.fit(inputs=[input_data],
job_name="modelarts_training_job_with_sdk_by_command_v01")
|
参数名称 |
参数说明 |
|---|---|
|
session |
modelarts session |
|
training_files |
训练代码的路径和启动文件 |
|
user_image_url |
自定义镜像swr地址,由镜像仓库组织/镜像名称:镜像tag组成 |
|
user_command |
执行训练命令 |
|
train_instance_type |
本地调测'local'或云端资源规格。每个region的资源规格可能是不同的,可以通过下述说明查询对应的资源规格信息。 |
|
train_instance_count |
节点数 |
|
log_url |
日志输出路径 |
|
job_name |
作业名称,不可以重复 |

train_instance_type表示训练的资源规格,每个region的资源规格可能是不同的。通过如下方法查询资源规格:
- 公共资源池执行如下命令查询
from modelarts.session import session from modelarts.estimatorv2 import estimator from pprint import pprint # 认证用的ak和sk硬编码到代码中或者明文存储都有很大的安全风险,建议在配置文件或者环境变量中密文存放,使用时解密,确保安全; # 本示例以ak和sk保存在环境变量中来实现身份验证为例,运行本示例前请先在本地环境中设置环境变量huaweicloud_sdk_ak和huaweicloud_sdk_sk。 __ak = os.environ["huaweicloud_sdk_ak"] __sk = os.environ["huaweicloud_sdk_sk"] # 如果进行了加密还需要进行解密操作 session = session(access_key=__ak,secret_key=__sk, project_id='***', region_name='***') info = estimator.get_train_instance_types(session=session) pprint(info)
- 专属池规格
modelarts专属资源池统一使用虚拟子规格,不区分gpu和ascend。资源规格参考表2查询。
|
train_instance_type |
说明 |
|---|---|
|
modelarts.pool.visual.xlarge |
1卡 |
|
modelarts.pool.visual.2xlarge |
2卡 |
|
modelarts.pool.visual.4xlarge |
4卡 |
|
modelarts.pool.visual.8xlarge |
8卡 |
步骤6:清除资源
notebook在代码调试完成及提交训练作业后就可以关闭了,减少资源扣费。
当调测完成且实例处于运行状态时,单击停止;
当下次调测且实例处于停止状态时,单击启动实例,随开随用。
训练输出保存结构说明
modelarts训练作业的模型输出和日志信息会定时同步到指定的obs中,本示例中模型输出路径和日志输出路径分别为f"{default_obs_dir}/mindspore_model/output/"和f"{default_obs_dir}/mindspore_model/logs/",用户可以在obs中查看训练输出信息。
本示例中训练输出保存在obs的目录结构如下所示:
${your_bucket}
└── intermidiate
├── dataset
│ └── flower_photos
│ └── flower_photos.zip
└── mindspore_model
├── logs
│ └── xxx-xxx-xxx--0.log
├── output
│ └── 20220627-105226-resnet50-224
└── mindspore-image-models.zip
提交训练作业常见问题
- 报错信息:exception: you have attempted to create more buckets than allowed
原因分析:由于桶的数量多于限额,无法自动创建。
解决方法:用户可以删除一个桶,或者直接指定一个已存在的桶(修改变量obs_bucket的值)。
- 报错信息:"errormessage":"the number of namespaces exceeds the upper limit"或"namespace is invalid"
原因分析:swr组织数限额,swr组织默认最多只能创建5个组织。
解决方法:用户可以删除一个swr组织,或者直接指定一个已存在的swr组织(修改变量image_organization的值)。
- 报错信息:standard_init_linux.go:224: exec user process caused "exet format error"
原因分析:可能由于训练规格错误导致训练作业卡死。
解决方法:请参考说明查询资源规格。
- 报错信息:报错镜像失败,报错:401,'unauthorized',b'{errors":[{"errorcode":"svcstg.swr.4010000",errormessage":"authenticate error",……}]
原因分析:远程连接notebook时需要输入鉴权信息。
解决方法:传入ak,sk信息。
1 2 3 4 5 6
# 认证用的ak和sk硬编码到代码中或者明文存储都有很大的安全风险,建议在配置文件或者环境变量中密文存放,使用时解密,确保安全; # 本示例以ak和sk保存在环境变量中来实现身份验证为例,运行本示例前请先在本地环境中设置环境变量huaweicloud_sdk_ak和huaweicloud_sdk_sk。 __ak = os.environ["huaweicloud_sdk_ak"] __sk = os.environ["huaweicloud_sdk_sk"] # 如果进行了加密还需要进行解密操作 session = session(access_key=__ak,secret_key=__sk, project_id='***', region_name='***')
相关文档
意见反馈
文档内容是否对您有帮助?
如您有其它疑问,您也可以通过华为云社区问答频道来与我们联系探讨




