在modelarts standard上运行gpu单机多卡训练作业-九游平台
操作流程
- 准备工作:
- 购买服务资源(vpc、sfs、swr和ecs)
- 配置权限
- 创建专属资源池(打通vpc)
- 在ecs服务器挂载sfs turbo存储
- 在ecs中设置modelarts用户可读权限
- 安装和配置obs命令行工具
- (可选)工作空间配置
- 模型训练:
本地构建镜像及调试
本节通过打包conda env来构建环境,也可以通过pip install、conda install等方式安装conda环境依赖。

- 容器镜像的大小建议小于15g,详细的自定义镜像规范要求请参见训练作业自定义镜像规范。
- 建议通过开源的官方镜像来构建,例如pytorch的官方镜像。
- 建议容器分层构建,单层容量不要超过1g、文件数不大于10w个。分层时,先构建不常变化的层,例如:先os,再cuda驱动,再python,再pytorch,再其他依赖包。
- 如果训练数据和代码经常变动,则不建议把数据、代码放到容器镜像里,避免频繁地构建容器镜像。
- 容器已经能满足隔离需求,不建议在容器内再创建多个conda env。
- 导出conda环境。
- 启动线下的容器镜像:
# run on terminal docker run -ti ${your_image:tag} - 在容器中输入如下命令,得到pytorch.tar.gz:
# run on container # 基于想要迁移的base环境创建一个名为pytorch的conda环境 conda create --name pytorch --clone base pip install conda-pack #将pytorch env打包生成pytorch.tar.gz conda pack -n pytorch -o pytorch.tar.gz
- 将打包好的压缩包传到本地:
# run on terminal docker cp ${your_container_id}:/xxx/xxx/pytorch.tar.gz . - 将pytorch.tar.gz上传到obs并设置公共读,并在构建时使用wget命令获取、解压、清理。
- 启动线下的容器镜像:
- 构建新镜像。
基础镜像一般选用“ubuntu 18.04”的官方镜像,或者nvidia官方提供的带cuda驱动的镜像。相关镜像直接到dockerhub九游平台官网查找即可。
构建流程:安装所需的apt包、驱动,配置ma-user用户、导入conda环境、配置notebook依赖。
- 推荐使用dockerfile的方式构建镜像。这样既满足dockerfile可追溯及构建归档的需求,也保证镜像内容无冗余和残留。
- 每层构建的时候都尽量把tar包等中间态文件删除,保证最终镜像更小,清理缓存的方法可参考:。
- 构建参考样例
dockerfile样例:
from nvidia/cuda:11.3.1-cudnn8-devel-ubuntu18.04 user root # section1: add user ma-user whose uid is 1000 and user group ma-group whose gid is 100. if there already exists 1000:100 but not ma-user:ma-group, below code will remove it run default_user=$(getent passwd 1000 | awk -f ':' '{print $1}') || echo "uid: 1000 does not exist" && \ default_group=$(getent group 100 | awk -f ':' '{print $1}') || echo "gid: 100 does not exist" && \ if [ ! -z ${default_group} ] && [ ${default_group} != "ma-group" ]; then \ groupdel -f ${default_group}; \ groupadd -g 100 ma-group; \ fi && \ if [ -z ${default_group} ]; then \ groupadd -g 100 ma-group; \ fi && \ if [ ! -z ${default_user} ] && [ ${default_user} != "ma-user" ]; then \ userdel -r ${default_user}; \ useradd -d /home/ma-user -m -u 1000 -g 100 -s /bin/bash ma-user; \ chmod -r 750 /home/ma-user; \ fi && \ if [ -z ${default_user} ]; then \ useradd -d /home/ma-user -m -u 1000 -g 100 -s /bin/bash ma-user; \ chmod -r 750 /home/ma-user; \ fi && \ # set bash as default rm /bin/sh && ln -s /bin/bash /bin/sh # section2: config apt source and install tools needed. run sed -i "s@http://.*archive.ubuntu.com@http://repo.huaweicloud.com@g" /etc/apt/sources.list && \ sed -i "s@http://.*security.ubuntu.com@http://repo.huaweicloud.com@g" /etc/apt/sources.list && \ apt-get update && \ apt-get install -y ca-certificates curl ffmpeg git libgl1-mesa-glx libglib2.0-0 libibverbs-dev libjpeg-dev libpng-dev libsm6 libxext6 libxrender-dev ninja-build screen sudo vim wget zip && \ apt-get clean && \ rm -rf /var/lib/apt/lists/* user ma-user # section3: install miniconda and rebuild conda env run mkdir -p /home/ma-user/work/ && cd /home/ma-user/work/ && \ wget https://repo.anaconda.com/miniconda/miniconda3-py37_4.12.0-linux-x86_64.sh && \ chmod 777 miniconda3-py37_4.12.0-linux-x86_64.sh && \ bash miniconda3-py37_4.12.0-linux-x86_64.sh -bfp /home/ma-user/anaconda3 && \ wget https://${bucketname}.obs.cn-north-4.myhuaweicloud.com/${folder_name}/pytorch.tar.gz && \ mkdir -p /home/ma-user/anaconda3/envs/pytorch && \ tar -xzf pytorch.tar.gz -c /home/ma-user/anaconda3/envs/pytorch && \ source /home/ma-user/anaconda3/envs/pytorch/bin/activate && conda-unpack && \ /home/ma-user/anaconda3/bin/conda init bash && \ rm -rf /home/ma-user/work/* env path=/home/ma-user/anaconda3/envs/pytorch/bin:$path # section4: settings of jupyter notebook for pytorch env run source /home/ma-user/anaconda3/envs/pytorch/bin/activate && \ pip install ipykernel==6.7.0 --trusted-host https://repo.huaweicloud.com -i https://repo.huaweicloud.com/repository/pypi/simple && \ ipython kernel install --user --env path /home/ma-user/anaconda3/envs/pytorch/bin:$path --name=pytorch && \ rm -rf /home/ma-user/.local/share/jupyter/kernels/pytorch/logo-* && \ rm -rf ~/.cache/pip/* && \ echo 'export path=$path:/home/ma-user/.local/bin' >> /home/ma-user/.bashrc && \ echo 'export ld_library_path=$ld_library_path:/usr/local/nvidia/lib64' >> /home/ma-user/.bashrc && \ echo 'conda activate pytorch' >> /home/ma-user/.bashrc env default_conda_env_name=pytorch
dockerfile中的"https://${bucket_name}.obs.cn-north-4.myhuaweicloud.com/${folder_name}/pytorch.tar.gz",需要替换为1中pytorch.tar.gz在obs上的路径(需将文件设置为公共读)。
进入dockerfile目录,通过dockerfile构建镜像命令:
# cd 到dockerfile所在目录下,输入构建命令 # docker build -t ${image_name}:${image_version} . # 例如 docker build -t pytorch-1.13-cuda11.3-cudnn8-ubuntu18.04:v1 . - 调试镜像
建议把调试过程中的修改点通过dockerfile固化到容器构建正式流程,并重新测试。
- 确认对应的脚本、代码、流程在linux服务器上运行正常。
如果在linux服务器上运行就有问题,那么先调通以后再做容器镜像。
- 确认打入镜像的文件是否在正确的位置、是否有正确的权限。
训练场景主要查看自研的依赖包是否正常,查看pip list是否包含所需的包,查看容器直接调用的python是否是自己所需要的那个(如果容器镜像装了多个python,需要设置python路径的环境变量)。
- 测试训练启动脚本。
- 优先使用手工进行数据复制的工作并验证
一般在镜像里不包含训练所用的数据和代码,所以在启动镜像以后需要手工把需要的文件复制进去。建议数据、代码和中间数据都放到"/cache"目录,防止正式运行时磁盘占满。建议linux服务器申请的时候,有足够大的内存(8g以上)以及足够大的硬盘(100g以上)。
docker和linux的文件交互命令如下:
docker cp data/ 39c9ceedb1f6:/cache/
数据准备完成后,启动训练的脚本,查看训练是否能够正常拉起。一般来说,启动脚本为:
cd /cache/code/ python start_train.py
如果训练流程不符合预期,可以在容器实例中查看日志、错误等,并进行代码、环境变量的修正。
- 预置脚本测试整体流程
一般使用run.sh封装训练外的文件复制工作(数据、代码:obs-->容器,输出结果:容器-->obs),run.sh的构建方法参考基于modelarts standard运行gpu训练作业。
如果预置脚本调用结果不符合预期,可以在容器实例中进行修改和迭代。
- 针对专属池场景
由于专属池支持sfs挂载,因此代码、数据的导入会更简单,甚至可以不用再关注obs的相关操作。
可以直接把sfs的目录直接挂载到调试节点的"/mnt/sfs_turbo"目录,或者保证对应目录的内容和sfs盘匹配。
调试时建议使用接近的方式,即:启动容器实例时使用"-v"参数来指定挂载某个宿主机目录到容器环境。
docker run -ti -d -v /mnt/sfs_turbo:/sfs my_deeplearning_image:v1
上述命令表示把宿主机的"/mnt/sfs_turbo"目录挂载到容器的"/sfs"目录,在宿主机和容器对应目录的所有改动都是实时同步的。
- 优先使用手工进行数据复制的工作并验证
- 分析错误时:训练镜像先看日志,推理镜像先看api的返回。
可以通过命令查看容器输出到stdout的所有日志:
docker logs -f 39c9ceedb1f6
一般在做推理镜像时,部分日志是直接存储在容器内部的,所以需要进入容器看日志。注意:重点对应日志中是否有error(包括,容器启动时、api执行时)。
- 牵扯部分文件用户组不一致的情况,可以在宿主机用root权限执行命令进行修改
docker exec -u root:root 39c9ceedb1f6 bash -c "chown -r ma-user:ma-user /cache"
- 针对调试中遇到的错误,可以直接在容器实例里修改,修改结果可以通过commit命令持久化。
- 确认对应的脚本、代码、流程在linux服务器上运行正常。
上传镜像
客户端上传镜像,是指在安装了容器引擎客户端的机器上使用docker命令将镜像上传到容器镜像服务的镜像仓库。
如果容器引擎客户端机器为云上的ecs或cce节点,根据机器所在区域有两种网络链路可以选择:
- 如果机器与容器镜像仓库在同一区域,则上传镜像走内网链路。
- 如果机器与容器镜像仓库不在同一区域,则上传镜像走公网链路,机器需要绑定弹性公网ip。
- 使用客户端上传镜像,镜像的每个layer大小不能大于10g。
- 上传镜像的容器引擎客户端版本必须为1.11.2及以上。
- 连接容器镜像服务。
- 登录容器镜像服务控制台。
- 单击右上角“创建组织”,输入组织名称完成组织创建。请自定义组织名称,本示例使用“deep-learning”,下面的命令中涉及到组织名称“deep-learning”也请替换为自定义的值。
- 选择左侧导航栏的“总览”,单击页面右上角的“登录指令”,在弹出的页面中单击
 复制登录指令。
复制登录指令。
- 此处生成的登录指令有效期为24小时,如果需要长期有效的登录指令,请参见获取长期有效登录指令。获取了长期有效的登录指令后,在有效期内的临时登录指令仍然可以使用。
- 登录指令末尾的域名为镜像仓库地址,请记录该地址,后面会使用到。
- 在安装容器引擎的机器中执行上一步复制的登录指令。
登录成功会显示“login succeeded”。
- 在安装容器引擎的机器上执行如下命令,为镜像打标签。
docker tag [镜像名称1:版本名称1] [镜像仓库地址]/[组织名称]/[镜像名称2:版本名称2]
- [镜像名称1:版本名称1]:${image_name}:${image_version}请替换为您所要上传的实际镜像的名称和版本名称。
- [镜像仓库地址]:可在swr控制台上查询,即1.c中登录指令末尾的域名。
- [组织名称]:/${organization_name}请替换为您创建的组织。
- [镜像名称2:版本名称2]:${image_name}:${image_version}请替换为您期待的镜像名称和镜像版本。
示例:
docker tag ${image_name}:${image_version} swr.cn-north-4.myhuaweicloud.com/${organization_name}/${image_name}:${image_version} - 上传镜像至镜像仓库。
docker push [镜像仓库地址]/[组织名称]/[镜像名称2:版本名称2]
示例:
docker push swr.cn-north-4.myhuaweicloud.com/${organization_name}/${image_name}:${image_version}上传镜像完成后,返回容器镜像服务控制台,在“我的镜像”页面,执行刷新操作后可查看到对应的镜像信息。
上传数据和算法至sfs
- ecs服务器已挂载sfs,请参考在ecs服务器挂载sfs turbo存储。
- 已经在ecs中设置权限,请参考在ecs中设置modelarts用户可读权限。
- 已经安装和配置obsutil,请参见安装和配置obs命令行工具。
- 准备数据
- 登录coco数据集下载九游平台官网地址:
- 下载coco2017数据集的train(18gb)、val images(1gb)、train/val annotations(241mb),分别解压后并放入coco文件夹中。
- 下载完成后,将数据上传至sfs相应目录中。由于数据集过大,推荐先通过obsutil工具将数据集传到obs桶后,再将数据集迁移至sfs。
- 在本机机器上运行,通过obsutil工具将本地数据集传到obs桶。
# 将本地数据传至obs中 # ./obsutil cp ${数据集所在的本地文件夹路径} ${存放数据集的obs文件夹路径} -f -r # 例如 ./obsutil cp ./coco obs://your_bucket/ -f -r - 登录ecs服务器,通过obsutil工具将数据集迁移至sfs,样例代码如下:
# 将obs数据传至sfs中 # ./obsutil cp ${数据集所在的obs文件夹路径} ${sfs文件夹路径} -f -r # 例如 ./obsutil cp obs://your_bucket/coco/ /mnt/sfs_turbo/ -f -r/mnt/sfs_turbo/coco文件夹内目录结构如下:
coco |---annotations |---train2017 |---val2017
更多obsutil的操作,可参考obsutil简介。
- 将文件设置归属为ma-user:
chown -r ma-user:ma-group coco
- 在本机机器上运行,通过obsutil工具将本地数据集传到obs桶。
- 准备算法
- 下载yolox代码。代码仓地址:。
git clone https://github.com/megvii-basedetection/yolox.git cd yolox git checkout 4f8f1d79c8b8e530495b5f183280bab99869e845
- 修改“requirements.txt”中的onnx版本,改为“onnx>=1.12.0”。
- 将“yolox/data/datasets/coco.py”第59行的“data_dir = os.path.join(get_yolox_datadir(), "coco")”改为“data_dir = '/home/ma-user/coco'”。
# data_dir = os.path.join(get_yolox_datadir(), "coco") data_dir = '/home/ma-user/coco'
- 在“tools/train.py”的第13行前加两句代码。
# 加上这两句代码,防止运行时找不到yolox module import sys sys.path.append(os.getcwd()) # line13 from yolox.core import launch from yolox.exp import exp, get_exp
- 将“yolox/layers/jit_ops.py”第122行的“fast_cocoeval”改为“fast_coco_eval_api”。
# def __init__(self, name="fast_cocoeval"): def __init__(self, name="fast_coco_eval_api"):
- 将“yolox\evaluators\coco_evaluator.py”第294行的“from yolox.layers import cocoeval_opt as cocoeval”改为“from pycocotools.cocoeval import cocoeval”。
try: # from yolox.layers import cocoeval_opt as cocoeval from pycocotools.cocoeval import cocoeval except importerror: from pycocotools.cocoeval import cocoeval logger.warning("use standard cocoeval.") - 在tools目录下新建一个“run.sh”作为启动脚本,“run.sh”内容可参考:
#!/usr/bin/env sh set -x set -o pipefail export nccl_debug=info default_one_gpu_batch_size=32 batch_size=$((${ma_num_gpus:-8} * ${vc_worker_num:-1} * ${default_one_gpu_batch_size})) if [ ${vc_worker_hosts} ];then yolox_dist_url=tcp://$(echo ${vc_worker_hosts} | cut -d "," -f 1):6666 /home/ma-user/anaconda3/envs/pytorch/bin/python -u tools/train.py \ -n yolox-s \ --devices ${ma_num_gpus:-8} \ --batch-size ${batch_size} \ --fp16 \ --occupy \ --num_machines ${vc_worker_num:-1} \ --machine_rank ${vc_task_index:-0} \ --dist-url ${yolox_dist_url} else /home/ma-user/anaconda3/envs/pytorch/bin/python -u tools/train.py \ -n yolox-s \ --devices ${ma_num_gpus:-8} \ --batch-size ${batch_size} \ --fp16 \ --occupy \ --num_machines ${vc_worker_num:-1} \ --machine_rank ${vc_task_index:-0} fi
部分环境变量在notebook环境中不存在,因此需要提供默认值。
- 将代码放到obs上,然后通过obs将代码传至sfs相应目录中。
- 在本机机器上运行,通过obsutil工具将本地数据集传到obs桶。
# 将本地代码传至obs中 ./obsutil cp ./yolox obs://your_bucket/ -f -r
- 登录ecs服务器,通过obsutil工具将数据集迁移至sfs,样例代码如下:
# 将obs的代码传到sfs中 ./obsutil cp obs://your_bucket/yolox/ /mnt/sfs_turbo/code/ -f -r
本案例中以obsutils方式上传文件,除此之外也可通过scp方式上传文件,具体操作步骤可参考本地linux主机使用scp上传文件到linux云服务器。
- 在本机机器上运行,通过obsutil工具将本地数据集传到obs桶。
- 在sfs中将文件设置归属为ma-user。
chown -r ma-user:ma-group yolox
- 执行以下命令,去除shell脚本的\r字符。
cd yolox sed -i 's/\r//' run.sh
shell脚本在windows系统编写时,每行结尾是\r\n,而在linux系统中行每行结尾是\n,所以在linux系统中运行脚本时,会认为\r是一个字符,导致运行报错“$'\r': command not found”,因此需要去除shell脚本的\r字符。
- 下载yolox代码。代码仓地址:。
使用notebook进行代码调试
- notebook使用涉及到计费,具体收费项如下:
- 处于“运行中”状态的notebook,会消耗资源,产生费用。根据您选择的资源不同,收费标准不同,价格详情请参见。当您不需要使用notebook时,建议停止notebook,避免产生不必要的费用。
- 创建notebook时,如果选择使用云硬盘evs存储配置,云硬盘evs会一直收费,建议及时停止并删除notebook,避免产生不必要的费用。
- 在创建notebook时,默认会开启自动停止功能,在指定时间内停止运行notebook,避免资源浪费。
- 只有处于“运行中”状态的notebook,才可以执行打开、停止操作。
- 一个账户最多创建10个notebook。
操作步骤如下:
- 注册镜像。登录modelarts控制台,在左侧导航栏选择“镜像管理”,进入镜像管理页面。单击“注册镜像”,镜像源即为推送到swr中的镜像。请将完整的swr地址复制到这里即可,或单击
 可直接从swr选择自有镜像进行注册,类型加上“gpu”,如图1所示。
图1 注册镜像
可直接从swr选择自有镜像进行注册,类型加上“gpu”,如图1所示。
图1 注册镜像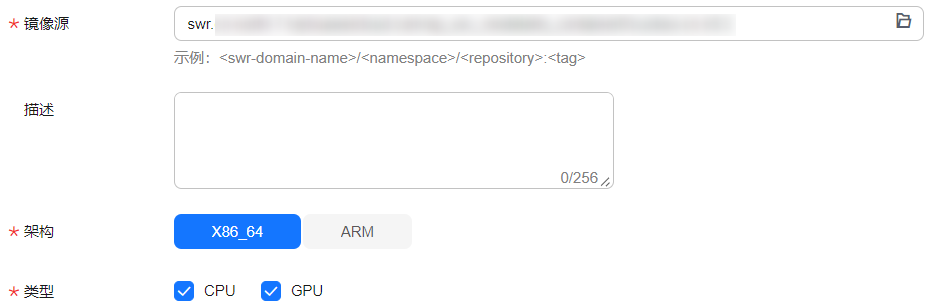
- 登录modelarts管理控制台,在左侧导航栏中选择“开发空间 > notebook”,进入“notebook”列表页面。
- 单击“创建notebook”,进入“创建notebook”页面,请参见如下说明填写参数。
- 填写notebook基本信息,包含名称、描述、是否自动停止,详细参数请参见表1。
表1 基本信息的参数描述 参数名称
说明
“名称”
notebook的名称。只能包含数字、大小写字母、下划线和中划线,长度不能大于64位且不能为空。
“描述”
对notebook的简要描述。
“自动停止”
默认开启,且默认值为“1小时”,表示该notebook实例将在运行1小时之后自动停止,即1小时后停止规格资源计费。
开启自动停止功能后,可选择“1小时”、“2小时”、“4小时”、“6小时”或“自定义”几种模式。选择“自定义”模式时,可指定1~24小时范围内任意整数。
- 填写notebook详细参数,如镜像、资源规格等。
- 镜像:在“自定义镜像”页签选择已上传的自定义镜像。
- 资源类型:按实际情况选择已创建的专属资源池。
- 规格:选择8卡gpu规格,“run.sh”文件中默认ma_num_gpus为8卡,因此选择notebook规格时需要与ma_num_gpus默认值相同。
- 存储配置:选择“弹性文件服务sfs”作为存储位置。子目录挂载可不填写,如果需挂载sfs指定目录,则在子目录挂载处填写具体路径。
如果需要通过vs code连接notebook方式进行代码调试,则需开启“ssh远程开发”并选择密钥对,请参考vs code连接notebook方式介绍。
- 填写notebook基本信息,包含名称、描述、是否自动停止,详细参数请参见表1。
- 参数填写完成后,单击“立即创建”进行规格确认。
- 参数确认无误后,单击“提交”,完成notebook的创建操作。
进入notebook列表,正在创建中的notebook状态为“创建中”,创建过程需要几分钟,请耐心等待。当notebook状态变为“运行中”时,表示notebook已创建并启动完成。
- 在notebook列表,单击实例名称,进入实例详情页,查看notebook实例配置信息。
- 在notebook中打开terminal,输入启动命令调试代码。
# 建立数据集软链接 # ln -s /home/ma-user/work/${coco数据集在sfs上的路径} /home/ma-user/coco # 进入到对应目录 # cd /home/ma-user/work/${yolox在sfs上的路径} # 安装环境并执行脚本 # /home/ma-user/anaconda3/envs/pytorch/bin/pip install -r requirements.txt && /bin/sh tools/run.sh # 例如 ln -s /home/ma-user/work/coco /home/ma-user/coco cd /home/ma-user/work/code/yolox/ /home/ma-user/anaconda3/envs/pytorch/bin/pip install -r requirements.txt && /bin/sh tools/run.sh
notebook中调试完后,如果镜像有修改,可以保存镜像用于后续训练,具体操作请参见保存notebook镜像环境。
创建单机多卡训练作业
- 登录modelarts管理控制台,检查当前账号是否已完成访问授权的配置。如果未完成,请参考使用委托授权针对之前使用访问密钥授权的用户,建议清空授权,然后使用委托进行授权。
- 在左侧导航栏中选择“模型训练 > 训练作业”,默认进入“训练作业”列表。单击“创建训练作业”进入创建训练作业页面。
- 在“创建训练作业”页面,填写相关参数信息,然后单击“提交”。
- 创建方式:选择“自定义算法”。
- 启动方式:选择“自定义”。
- 镜像:选择上传的自定义镜像。
- 启动命令:
ln -s /home/ma-user/work/coco /home/ma-user/coco && cd /home/ma-user/work/code/yolox/ && /home/ma-user/anaconda3/envs/pytorch/bin/pip install -r requirements.txt && /bin/sh tools/run.sh
- 资源池:在“专属资源池”页签选择gpu规格的专属资源池。
- 规格:选择8卡gpu规格。
- 计算节点:1。
- sfs turbo:增加挂载配置,选择sfs名称,云上挂载路径为“/home/ma-user/work”。
为了和notebook调试时代码路径一致,保持相同的启动命令,因此云上挂载路径需要填写为“/home/ma-user/work”。
- 单击“提交”,在“信息确认”页面,确认训练作业的参数信息,确认无误后单击“确定”。
- 训练作业创建完成后,后台将自动完成容器镜像下载、代码目录下载、执行启动命令等动作。
训练作业一般需要运行一段时间,根据您的训练业务逻辑和选择的资源不同,训练时长将持续几十分钟到几小时不等。
相关文档
意见反馈
文档内容是否对您有帮助?
如您有其它疑问,您也可以通过华为云社区问答频道来与我们联系探讨




