cogvideox模型基于lite server适配pytorch npu全量训练指导(6.3.911)-九游平台
本文档主要介绍如何在modelarts的lite server环境中,使用npu卡对cogvideox模型基于sat框架进行全量微调。本文档中提供的脚本,是基于原生cogvideox的代码基础适配修改,可以用于npu芯片训练。
cogvideo是一个94亿参数的transformer模型,用于文本到视频生成。通过继承一个预训练的文本到图像模型cogview2,还提出了多帧速率分层训练策略,以更好地对齐文本和视频剪辑。作为一个开源的大规模预训练文本到视频模型,cogvideo性能优于所有公开可用的模型,在机器和人类评估方面都有很大的优势。
方案概览
本方案介绍了在modelarts的lite server上使用昇腾计算资源开展cogvideox-2b/5b全量微调的详细过程。完成本方案的部署,需要先联系您所在企业的华为方九游平台的技术支持购买lite server资源。
本方案目前仅适用于企业客户。
资源规格要求
推荐使用“西南-贵阳一”region上的lite server资源和ascend snt9b单机。
|
名称 |
版本 |
|---|---|
|
driver |
23.0.6 |
|
pytorch |
pytorch_2.1.0 |
获取软件和镜像
|
分类 |
名称 |
获取路径 |
|---|---|---|
|
插件代码包 |
ascendcloud-6.3.911-xxx.zip软件包中的ascendcloud-aigc-6.3.911-xxx.zip
说明:
包名中的xxx表示具体的时间戳,以包名的实际时间为准。 |
获取路径:,在此路径中查找下载modelarts 6.3.911 版本。
说明:
如果上述软件获取路径打开后未显示相应的软件信息,说明您没有下载权限,请联系您所在企业的华为方九游平台的技术支持下载获取。 |
|
基础镜像 |
西南-贵阳一: swr.cn-southwest-2.myhuaweicloud.com/atelier/pytorch_2_1_ascend:pytorch_2.1.0-cann_8.0.rc3-py_3.9-hce_2.0.2409-aarch64-snt9b-20241112192643-c45ac6b |
从swr拉取。 |
约束限制
- 本文档适配昇腾云modelarts 6.3.911版本,请参考表2获取配套版本的软件包和镜像,请严格遵照版本配套关系使用本文档。
- 确保容器可以访问公网。
步骤一:准备环境
- 请参考,购买lite server资源,并确保机器已开通,密码已获取,能通过ssh登录,不同机器之间网络互通。

当容器需要提供服务给多个用户,或者多个用户共享使用该容器时,应限制容器访问openstack的管理地址(169.254.169.254),以防止容器获取宿主机的元数据。具体操作请参见。
- ssh登录机器后,检查npu设备检查。运行如下命令,返回npu设备信息。
npu-smi info # 在每个实例节点上运行此命令可以看到npu卡状态 npu-smi info -l | grep total # 在每个实例节点上运行此命令可以看到总卡数
如出现错误,可能是机器上的npu设备没有正常安装,或者npu镜像被其他容器挂载。请先正常安装固件和驱动,或释放被挂载的npu。
- 检查docker是否安装。
docker -v #检查docker是否安装
如尚未安装,运行以下命令安装docker。
yum install -y docker-engine.aarch64 docker-engine-selinux.noarch docker-runc.aarch64
- 配置ip转发,用于容器内的网络访问。执行以下命令查看net.ipv4.ip_forward配置项的值,如果为1,可跳过此步骤。
sysctl -p | grep net.ipv4.ip_forward
如果net.ipv4.ip_forward配置项的值不为1,执行以下命令配置ip转发。sed -i 's/net\.ipv4\.ip_forward=0/net\.ipv4\.ip_forward=1/g' /etc/sysctl.conf sysctl -p | grep net.ipv4.ip_forward
步骤三:启动容器镜像
- 启动容器镜像。启动前请先按照参数说明修改${}中的参数。
export work_dir="自定义挂载的工作目录" export container_work_dir="自定义挂载到容器内的工作目录" export container_name="自定义容器名称" export image_name="镜像名称或id" // 启动一个容器去运行镜像 docker run -itd --net=bridge \ --device=/dev/davinci0 \ --device=/dev/davinci1 \ --device=/dev/davinci2 \ --device=/dev/davinci3 \ --device=/dev/davinci4 \ --device=/dev/davinci5 \ --device=/dev/davinci6 \ --device=/dev/davinci7 \ --device=/dev/davinci_manager \ --device=/dev/devmm_svm \ --device=/dev/hisi_hdc \ --shm-size=32g \ -v /usr/local/dcmi:/usr/local/dcmi \ -v /usr/local/ascend/driver:/usr/local/ascend/driver \ -v /var/log/npu/:/usr/slog \ -v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \ -v ${work_dir}:${container_work_dir} \ --name ${container_name} \ ${image_name} \ /bin/bash参数说明:
- -v ${work_dir}:${container_work_dir}:代表需要在容器中挂载宿主机的目录。宿主机和容器使用不同的文件系统。work_dir为宿主机中工作目录,目录下可存放项目所需代码、数据等文件。container_work_dir为要挂载到的容器中的目录。为方便两个地址可以相同。
- 容器不能挂载到/home/ma-user目录,此目录为ma-user用户家目录。如果容器挂载到/home/ma-user下,拉起容器时会与基础镜像冲突,导致基础镜像不可用。
- driver及npu-smi需同时挂载至容器。
- --name ${container_name}:容器名称,进入容器时会用到,此处可以自己定义一个容器名称。
- ${image_name}:容器镜像的名称。
- --device=/dev/davinci0 :挂载对应卡到容器,当需要挂载多卡,请依次添加多项该配置
- -v ${work_dir}:${container_work_dir}:代表需要在容器中挂载宿主机的目录。宿主机和容器使用不同的文件系统。work_dir为宿主机中工作目录,目录下可存放项目所需代码、数据等文件。container_work_dir为要挂载到的容器中的目录。为方便两个地址可以相同。
- 通过容器名称进入容器中。默认使用ma-user用户,后续所有操作步骤都在ma-user用户下执行。
docker exec -it ${container_name} bash
步骤四:安装依赖和软件包
- git clone和git lfs下载大模型可以参考如下操作。
- 由于欧拉源上没有git-lfs包,所以需要从压缩包中解压使用,在浏览器中输入如下地址下载git-lfs压缩包并上传到容器的/home/ma-user目录下。
https://github.com/git-lfs/git-lfs/releases/download/v3.2.0/git-lfs-linux-arm64-v3.2.0.tar.gz
或直接下载到容器,这样在容器中可以直接使用。cd /home/ma-user wget https://github.com/git-lfs/git-lfs/releases/download/v3.2.0/git-lfs-linux-arm64-v3.2.0.tar.gz
- 进入容器,执行安装git lfs命令。
cd /home/ma-user tar -zxvf git-lfs-linux-arm64-v3.2.0.tar.gz cd git-lfs-3.2.0 sudo sh install.sh
- 设置git配置去掉ssl校验。
git config --global http.sslverify false
- 由于欧拉源上没有git-lfs包,所以需要从压缩包中解压使用,在浏览器中输入如下地址下载git-lfs压缩包并上传到容器的/home/ma-user目录下。
- 从github拉取cogvideox代码。
cd /home/ma-user git clone https://github.com/thudm/cogvideo.git cd /home/ma-user/cogvideo git checkout v1.0
- 若进行训练微调需依赖decord和triton包,arm版本可参考附录安装编译。
- 安装cogvideo ascend软件包。
- 将获取到的cogvideo ascend软件包ascendcloud-aigc-*.zip文件上传到容器的/home/ma-user目录下。获取路径参见获取软件和镜像。
- 解压ascendcloud-aigc-*.zip文件,解压后将里面指定文件与对应cogvideo文件进行替换,执行以下命令即可。
cd /home/ma-user unzip ascendcloud-aigc-*.zip -d ./ascendcloud cd ascendcloud/multimodal_algorithm/cogvideo_v1_sft/ dos2unix install.sh bash install.sh
ascendcloud-aigc-*.zip后面的*表示时间戳,请按照实际替换。
cogvideo ascend软件包内容如下:. |---- install.sh 安装torch-npu适配修改脚本 |---- modify.patch 适配cogvideo训练代码git patch文件 |---- readme.md 适配文档基于官方代码commit id说明 |---- requirements.txt python依赖包 |---- vae_cache.py vae_cache文件 |---- vae_cache.sh vae_cache脚本
步骤五:cogvideo微调
- 下载模型权重
首先,前往sat镜像下载模型权重。对于cogvideox-2b模型,请按照如下方式下载。
mkdir cogvideox-2b-sat cd cogvideox-2b-sat wget https://cloud.tsinghua.edu.cn/f/fdba7608a49c463ba754/?dl=1 mv 'index.html?dl=1' vae.zip unzip vae.zip wget https://cloud.tsinghua.edu.cn/f/556a3e1329e74f1bac45/?dl=1 mv 'index.html?dl=1' transformer.zip unzip transformer.zip
请按如下链接方式下载cogvideox-5b模型的transformers文件(vae 文件与 2b 相同):。
接着,需要将模型文件排版成如下格式。
. ├── transformer │ ├── 1000 (or 1) │ │ └── mp_rank_00_model_states.pt │ └── latest └── vae └── 3d-vae.pt将对应模型下载至容器内。
#cogvideox-2b模型地址 https://huggingface.co/thudm/cogvideox-2b #cogvideox-5b模型地址 https://huggingface.co/thudm/cogvideox-5b
克隆t5模型,该模型不用做训练和微调,但是必须使用。
5b模型参考如下,2b模型请修改对应路径 mkdir t5-v1_1-xxl mv cogvideox-5b/text_encoder/* cogvideox-5b/tokenizer/* t5-v1_1-xxl
通过上述方案,将会得到一个safetensor格式的t5文件,确保在deepspeed微调过程中读入的时候不会报错。
├── added_tokens.json ├── config.json ├── model-00001-of-00002.safetensors ├── model-00002-of-00002.safetensors ├── model.safetensors.index.json ├── special_tokens_map.json ├── spiece.model └── tokenizer_config.json 0 directories, 8 files
- 准备数据集
数据集格式应该如下:
. ├── labels │ ├── 1.txt │ ├── 2.txt │ ├── ... └── videos ├── 1.mp4 ├── 2.mp4 ├── ...每个 txt 与视频同名,为视频的标签。视频与标签应该一一对应。通常情况下,不使用一个视频对应多个标签。
如果为风格微调,请准备至少50条风格相似的视频和标签,以利于拟合。
- 修改cogvideo/sat/configs/cogvideox_*.yaml文件
如果希望使用 lora 微调,需要修改cogvideox_<模型参数>_lora 文件,修改参考如下:
*** conditioner_config: target: sgm.modules.generalconditioner params: emb_models: - is_trainable: false input_key: txt ucg_rate: 0.1 target: sgm.modules.encoders.modules.frozent5embedder params: model_dir: "t5-v1_1-xxl" # cogvideox-5b/t5-v1_1-xxl 权重文件夹的绝对路径 max_length: 226 first_stage_config: target: vae_modules.autoencoder.videoautoencoderinferencewrapper params: cp_size: 1 ckpt_path: "cogvideox-5b-sat/vae/3d-vae.pt" # cogvideox-5b-sat/vae/3d-vae.pt文件夹的绝对路径 ignore_keys: [ 'loss' ] - 修改cogvideo/sat/configs/sft.yaml配置文件
支持lora和全参数微调两种方式。请注意,两种微调方式都仅对transformer部分进行微调。不改动vae部分,t5仅作为encoder使用。请按照以下方式修改configs/sft.yaml(全量微调) 中的文件。
# checkpoint_activations: true ## using gradient checkpointing (配置文件中的两个checkpoint_activations都需要设置为true) model_parallel_size: 1 # 模型并行大小 experiment_name: lora-disney # 实验名称(不要改动) mode: finetune # 模式(不要改动) load: "{your_cogvideox-5b-sat_path}/transformer" ## transformer 模型路径 no_load_rng: true # 是否加载随机数种子 train_iters: 500 # 训练迭代次数 eval_iters: 1 # 验证迭代次数 eval_interval: 300 # 验证间隔 eval_batch_size: 1 # 验证集 batch size save: ckpts # 模型保存路径 save_interval: 100 # 模型保存间隔 log_interval: 1 # 日志输出间隔 train_data: [ "your train data path" ] #训练集路径 valid_data: [ "your val data path" ] # 训练集和验证集可以相同 split: 1,0,0 # 训练集,验证集,测试集比例 num_workers: 8 # 数据加载器的工作线程数 force_train: true # 在加载checkpoint时允许missing keys (t5 和 vae 单独加载) only_log_video_latents: true # 避免vae decode带来的显存开销 deepspeed: bf16: enabled: false # for cogvideox-2b turn to false and for cogvideox-5b turn to true fp16: enabled: true # for cogvideox-2b turn to true and for cogvideox-5b turn to false - 修改运行脚本
编辑cogvideo/sat/finetune_multi_gpus.sh,选择配置文件。下面是两个例子:
- 如果您想使用cogvideox-5b模型并使用lora方案,需要修改finetune_multi_gpus.sh中参数参考如下:
--base configs/cogvideox_5b_lora.yaml
- 如果您想使用cogvideox-5b模型并使用全量微调方案,需要修改finetune_multi_gpus.sh中参数参考如下:
--base configs/cogvideox_5b.yaml
- 如果您想使用cogvideox-5b模型并使用lora方案,需要修改finetune_multi_gpus.sh中参数参考如下:
- 开始训练微调
修改cogvideo/sat/vae_cache.sh脚本,将vae模型部分进行预先缓存,也需要对vae_cache.sh脚本中参数修改参考如下:
--base configs/cogvideox_5b.yaml
运行微调脚本finetune_multi_gpus.shcd /home/ma-user/cogvideo/sat/ bash vae_cache.sh bash finetune_multi_gpus.sh
以上微调文档提示来自官方文档,有关可用微调脚本参数及其功能的全面文档,您可以参考。
附:decord和triton在arm版本安装参考
由于训练使用decord和triton的python包没有arm版本,请自行进行编译安装,以下给出安装编译教程仅供参考:
- decord包编译
可参考如下脚本:
bash install_decord.sh # install_decord.sh内容如下
install_decord.sh脚本内容如下:
cd /home/ma-user/ git config --global http.sslverify false git clone --recursive https://github.com/dmlc/decord --depth 1 cd decord mkdir build && cd build cmake .. -dcmake_build_type=release -dffmpeg_dir:path="/usr/local/ffmpeg/" make cd ../python ### option 1: add python path to $pythonpath, you will need to install numpy separately echo "pythonpath=$pythonpath:/home/ma-user/decord/python" >> ~/.bashrc source ~/.bashrc ### option 2: install with setuptools python3 setup.py install --user
- triton包编译:
本文档triton包基于commit id 8a3fb7e3fd6b87f09bcb4ebc6编译测试
cd /home/ma-user git clone https://github.com/triton-lang/triton.git cd /home/ma-user/triton git checkout 8a3fb7e3fd6b87f09bcb4ebc6 cd /home/ma-user/triton/python pip install ninja cmake wheel pybind11 pip install -e .
若编译过程出现所依赖的tar包下载失败,如下图所示:
图1 tar包下载失败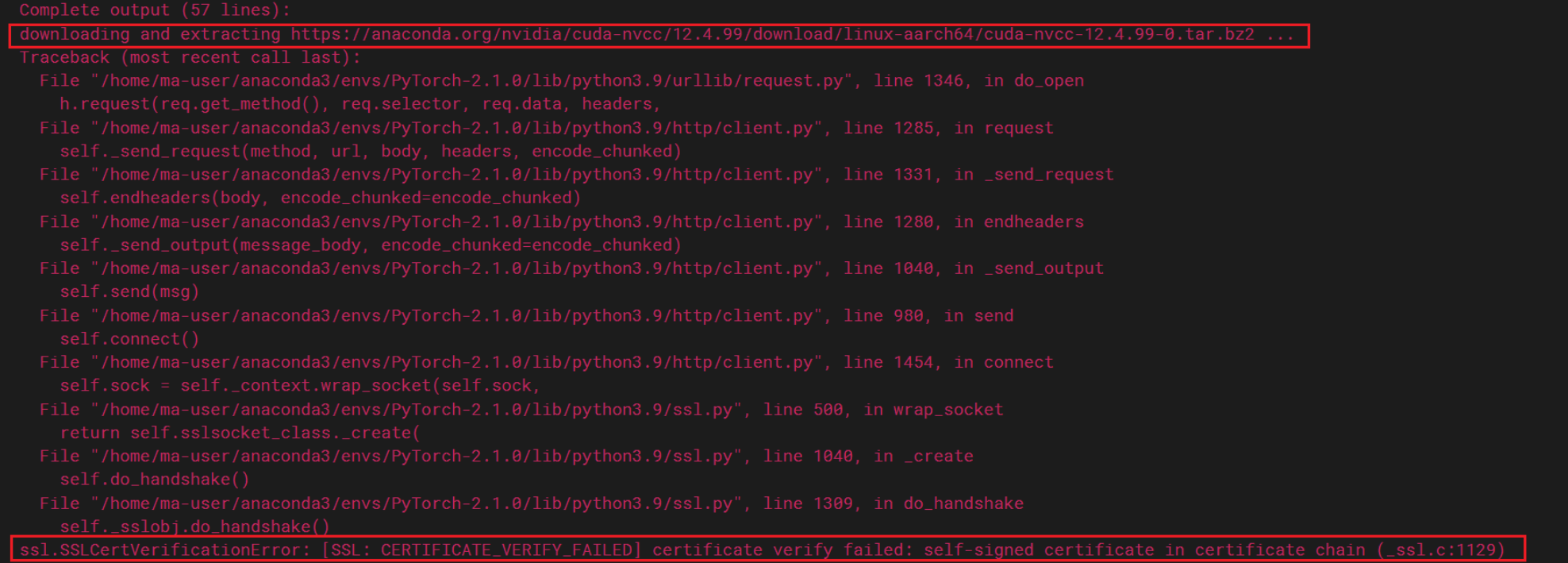
可设置ssl忽略证书验证,修改/home/ma-user/triton/python/setup.py文件,open_方法:
# 新增ssl忽略证书验证 import ssl context = ssl._create_unverified_context() # set timeout to 300 seconds to prevent the request from hanging forever. return urllib.request.urlopen(request, context=context, timeout=300)图2 设置ssl忽略证书验证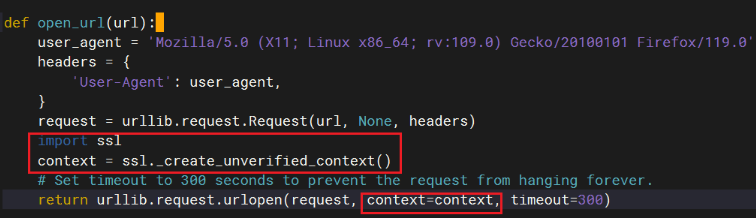
相关文档
意见反馈
文档内容是否对您有帮助?
如您有其它疑问,您也可以通过华为云社区问答频道来与我们联系探讨




