minicpm-九游平台
本文档主要介绍如何在modelarts lite的server环境中,使用npu卡对minicpm-v2.6进行lora微调及sft微调。本文档中提供的训练脚本,是基于原生minicpm-v的代码基础适配修改,可以用于npu芯片训练。
方案概览
本方案介绍了在modelarts的server上使用昇腾计算资源开展minicpm-v 2.6 lora训练的详细过程。完成本方案的部署,需要先联系您所在企业的华为方九游平台的技术支持购买server资源。
本方案目前仅适用于企业客户。
资源规格要求
推荐使用“西南-贵阳一”region上的server资源和ascend snt9b单机。
|
名称 |
版本 |
|---|---|
|
cann |
cann_8.0.rc3 |
|
驱动 |
24.1.rc1 |
|
pytorch |
2.1.0 |
获取软件和镜像
|
分类 |
名称 |
获取路径 |
|---|---|---|
|
插件代码包 |
ascendcloud-6.3.912-xxx.zip软件包中的ascendcloud-aigc-6.3.912-xxx.zip
说明:
包名中的xxx表示具体的时间戳,以包名的实际时间为准。 |
获取路径:,在此路径中查找下载modelarts 6.3.912版本。
说明:
如果上述软件获取路径打开后未显示相应的软件信息,说明您没有下载权限,请联系您所在企业的华为方九游平台的技术支持下载获取。 |
|
基础镜像 |
西南-贵阳一: swr.cn-southwest-2.myhuaweicloud.com/atelier/pytorch_2_1_ascend:pytorch_2.1.0-cann_8.0.rc3-py_3.9-hce_2.0.2409-aarch64-snt9b-20241213131522-aafe527 |
从swr拉取。 |
约束限制
- 本文档适配昇腾云modelarts 6.3.912版本,请参考表2获取配套版本的软件包和镜像,请严格遵照版本配套关系使用本文档。
- 确保容器可以访问公网。
step1 准备环境
- 请参考,购买server资源,并确保机器已开通,密码已获取,能通过ssh登录,不同机器之间网络互通。

当容器需要提供服务给多个用户,或者多个用户共享使用该容器时,应限制容器访问openstack的管理地址(169.254.169.254),以防止容器获取宿主机的元数据。具体操作请参见。
- ssh登录机器后,检查npu设备检查。运行如下命令,返回npu设备信息。
npu-smi info # 在每个实例节点上运行此命令可以看到npu卡状态 npu-smi info -l | grep total # 在每个实例节点上运行此命令可以看到总卡数
如出现错误,可能是机器上的npu设备没有正常安装,或者npu镜像被其他容器挂载。请先正常安装固件和驱动,或释放被挂载的npu。
- 检查docker是否安装。
docker -v #检查docker是否安装
如尚未安装,运行以下命令安装docker。
yum install -y docker-engine.aarch64 docker-engine-selinux.noarch docker-runc.aarch64
- 配置ip转发,用于容器内的网络访问。执行以下命令查看net.ipv4.ip_forward配置项的值,如果为1,可跳过此步骤。
sysctl -p | grep net.ipv4.ip_forward
如果net.ipv4.ip_forward配置项的值不为1,执行以下命令配置ip转发。sed -i 's/net\.ipv4\.ip_forward=0/net\.ipv4\.ip_forward=1/g' /etc/sysctl.conf sysctl -p | grep net.ipv4.ip_forward
step3 启动容器镜像
- 启动容器镜像。启动前请先按照参数说明修改${}中的参数。
export work_dir="自定义挂载的工作目录" export container_work_dir="自定义挂载到容器内的工作目录" export container_name="自定义容器名称" export image_name="镜像名称或id" // 启动一个容器去运行镜像 docker run -itd --net=bridge \ --device=/dev/davinci0 \ --device=/dev/davinci1 \ --device=/dev/davinci2 \ --device=/dev/davinci3 \ --device=/dev/davinci4 \ --device=/dev/davinci5 \ --device=/dev/davinci6 \ --device=/dev/davinci7 \ --device=/dev/davinci_manager \ --device=/dev/devmm_svm \ --device=/dev/hisi_hdc \ --shm-size=32g \ -v /usr/local/dcmi:/usr/local/dcmi \ -v /usr/local/ascend/driver:/usr/local/ascend/driver \ -v /var/log/npu/:/usr/slog \ -v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \ -v ${work_dir}:${container_work_dir} \ --name ${container_name} \ ${image_name} \ /bin/bash参数说明:
- -v ${work_dir}:${container_work_dir}:代表需要在容器中挂载宿主机的目录。宿主机和容器使用不同的文件系统。work_dir为宿主机中工作目录,目录下存放着训练所需代码、数据等文件。container_work_dir为要挂载到的容器中的目录。为方便两个地址可以相同。
- 容器不能挂载到/home/ma-user目录,此目录为ma-user用户家目录。如果容器挂载到/home/ma-user下,拉起容器时会与基础镜像冲突,导致基础镜像不可用。
- driver及npu-smi需同时挂载至容器。
- --name ${container_name}:容器名称,进入容器时会用到,此处可以自己定义一个容器名称。
- ${image_name}:容器镜像的名称。
- --device=/dev/davinci0 :挂载对应卡到容器,当需要挂载多卡,请依次添加多项该配置
- -v ${work_dir}:${container_work_dir}:代表需要在容器中挂载宿主机的目录。宿主机和容器使用不同的文件系统。work_dir为宿主机中工作目录,目录下存放着训练所需代码、数据等文件。container_work_dir为要挂载到的容器中的目录。为方便两个地址可以相同。
- 通过容器名称进入容器中。默认使用ma-user用户,后续所有操作步骤都在ma-user用户下执行。
docker exec -it -u ma-user ${container_name} bash
step4 安装依赖和软件包
- 从github拉取minicpm-v代码。
cd /home/ma-user git clone https://github.com/openbmb/minicpm-v.git cd /home/ma-user/minicpm-v git checkout c541f1044e7c0bb2ba48e3eb21daf070e90cd6a2
- 获取openbmb/minicpm-v-2_6模型。
https://huggingface.co/openbmb/minicpm-v-2_6
#手动下载模型权重放置在指定路径 sudo chown -r ma-user:ma-group ${container_work_dir} mkdir -p ${container_work_dir}/minicpm/minicpm-v-2_6/ cp -r minicpm-v-2_6 ${container_work_dir}/minicpm/minicpm-v-2_6/ - 准备coco数据集。
cd minicpm-v/finetune/ # download coco images wget http://images.cocodataset.org/zips/train2014.zip && unzip train2014.zip wget http://images.cocodataset.org/zips/val2014.zip && unzip val2014.zip
- 制作数据集,参考九游平台官网下面链接data preparation章节。
制成coco2014_train.json文件和coco2014_val.json放在minicpm-v/finetune/目录中。json文件示例如下。
图1 json文件示例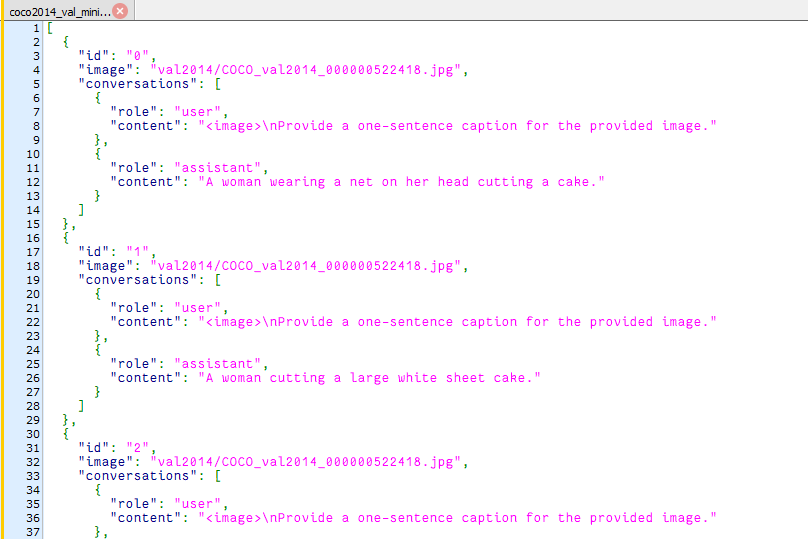
- 执行微调脚本前需要补充安装依赖包。
pip install accelerate pip install tensorboard pip install deepspeed==0.15.1 pip install peft pip install numpy==1.24.4 pip install transformers==4.40.0 pip install einops
step5 minicpm-v2.6微调前修改脚本
使用/home/ma-user/minicpm-v/finetune/finetune_lora.sh官方脚本对minicpm-v 2.6进行lora微调。使用/home/ma-user/minicpm-v/finetune/finetune_ds.sh官方脚本对minicpm-v 2.6进行sft微调。微调脚本默认使用 transformers trainer 和 deepspeed。
在 ds_config_zero2.json 修改overlap_comm为false。
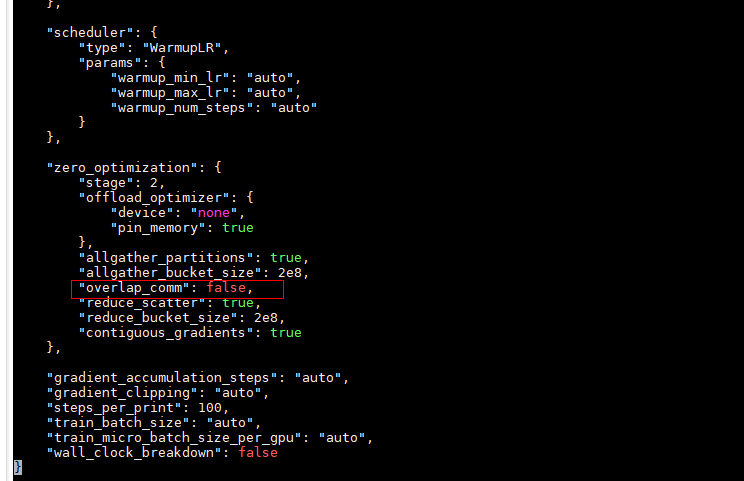
loss固定
pip install mindstudio-probe
在finetune.py脚本前添加
from msprobe.pytorch import seed_all seed_all(1234)
npu
在finetune.py脚本前添加
import torch_npu from torch_npu.contrib import transfer_to_npu
下载插件包ascendcloud-aigc-6.3.912-xxx.zip到${container_work_dir}并解压后得到multimodal_algorithm。
sudo chown -r ma-user:ma-group ${container_work_dir}
unzip ascendcloud-aigc-6.3.909-xxx.zip
cd ${container_work_dir}/multimodal_algorithm/ascendcloud_multimodal_plugin
pip install -e .
# 在minicpm-v/finetune/finetune.py引入优化代码包
from ascendcloud_multimodal.train.models.minicpmv.minicpmv2_6 import ascend_modeling_minicpmv2_6
step6 监督微调
bash finetune_ds.sh
修改模型权重路径${model_path},保持其余参数一致。脚本参数设置如下:
#!/bin/bash
gpus_per_node=8
nnodes=1
node_rank=0
master_addr=localhost
master_port=6001
model=${mdoel_path}
# or openbmb/minicpm-v-2, openbmb/minicpm-llama3-v-2_5
# attention: specify the path to your training data, which should be a json file consisting of a list of conversations.# see the section for finetuning in readme for more information.
data="coco2014_train.json"
eval_data="coco2014_val.json"
llm_type="qwen2" # if use openbmb/minicpm-v-2, please set llm_type=minicpm, if use openbmb/minicpm-llama3-v-2_5, please set llm_type="llama3"
model_max_length=2048 # if conduct multi-images sft, please set model_max_length=4096
distributed_args="
--nproc_per_node $gpus_per_node \
--nnodes $nnodes \
--node_rank $node_rank \
--master_addr $master_addr \
--master_port $master_port
"
torchrun $distributed_args finetune.py \
--model_name_or_path $model \
--llm_type $llm_type \
--data_path $data \
--eval_data_path $eval_data \
--remove_unused_columns false \
--label_names "labels" \
--prediction_loss_only false \
--bf16 true \
--bf16_full_eval true \
--fp16 false \
--fp16_full_eval false \
--do_train \
--do_eval \
--tune_vision true \
--tune_llm true \
--model_max_length $model_max_length \
--max_slice_nums 9 \
--max_steps 1000 \
--eval_steps 5000 \
--output_dir output/output_minicpmv26 \
--logging_dir output/output_minicpmv26 \
--logging_strategy "steps" \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 1 \
--evaluation_strategy "steps" \
--save_strategy "steps" \
--save_steps 2000 \
--save_total_limit 10 \
--learning_rate 1e-6 \
--weight_decay 0.1 \
--adam_beta2 0.95 \
--warmup_ratio 0.01 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--gradient_checkpointing true \
--deepspeed ds_config_zero2.json \
--report_to "tensorboard"
step7 lora微调
bash finetune_lora.sh
修改模型权重路径${model_path},保持其余参数一致。脚本参数设置如下:
#!/bin/bash
gpus_per_node=8
nnodes=1
node_rank=0
master_addr=localhost
master_port=6001
export pytorch_npu_alloc_conf=expandable_segments:true
model=${mdoel_path} # or openbmb/minicpm-v-2, openbmb/minicpm-llama3-v-2_5
# attention: specify the path to your training data, which should be a json file consisting of a list of conversations.
# see the section for finetuning in readme for more information.
data="coco2014_train.json"
eval_data="coco2014_val.json"
llm_type="qwen2"
# if use openbmb/minicpm-v-2, please set llm_type=minicpm#if use openbmb/minicpm-llama3-v-2_5, please set llm_type=llama3 model_max_length=2048
# if conduct multi-images sft, please set model_max_length=4096
model_max_length=2048
distributed_args="
--nproc_per_node $gpus_per_node \
--nnodes $nnodes \
--node_rank $node_rank \
--master_addr $master_addr \
--master_port $master_port
"
torchrun $distributed_args finetune.py \
--model_name_or_path $model \
--llm_type $llm_type \
--data_path $data \
--eval_data_path $eval_data \
--remove_unused_columns false \
--label_names "labels" \
--prediction_loss_only false \
--bf16 true \
--bf16_full_eval true \
--fp16 false \
--fp16_full_eval false \
--do_train \
--do_eval \
--num_train_epochs 1 \
--tune_vision true \
--tune_llm false \
--use_lora true \
--lora_target_modules "llm\..*layers\.\d \.self_attn\.(q_proj|k_proj|v_proj|o_proj)" \
--model_max_length $model_max_length \
--max_slice_nums 9 \
--max_steps 1000 \
--eval_steps 10000 \
--output_dir output/output__lora \
--logging_dir output/output_lora \
--logging_strategy "steps" \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 1 \
--evaluation_strategy "steps" \
--save_strategy "steps" \
--save_steps 10000 \
--save_total_limit 10 \
--learning_rate 1e-6 \
--weight_decay 0.1 \
--adam_beta2 0.95 \
--warmup_ratio 0.01 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--gradient_checkpointing true \
--deepspeed ds_config_zero2.json \
--report_to "tensorboard"
相关文档
意见反馈
文档内容是否对您有帮助?
如您有其它疑问,您也可以通过华为云社区问答频道来与我们联系探讨




