大数据场景下使用obs实现存算分离方案概述-九游平台
应用场景
随着大数据技术的飞速发展,对数据价值的认识逐渐加深,大数据已经融入到了各行各业。根据相关调查报告数据显示,超过39.6%的企业正在应用大数据并从中获益;超过89.6%的企业已经成立或计划成立相关的大数据分析部门;超过六成的企业在扩大大数据的投入力度。对各行业来讲,大数据的使用能力成为未来取得竞争优势的关键能力之一。
在大数据场景下,数据已成为新资产,智能已成为新生产力。企业迫切需要完成数字化转型,提高生产力,使数据资产发挥最大价值。而传统企业在业务未上云之前,业务部署和数据存储往往都在本地idc机房的多个集群,且一台服务器同时提供计算和存储能力,这种方式导致的如表1所示的几个关键问题,已成为企业数字化转型的阻碍。
|
序号 |
关键问题 |
详细描述 |
|---|---|---|
|
1 |
多集群数据共享难 |
企业数据往往分别存储在idc多个集群,存在如下问题:
|
|
2 |
计算存储资源绑定,导致资源浪费 |
计算和存储资源无法均衡,当计算和存储需求不一致时,只能等比扩容,势必造成一种资源的浪费。 |
|
3 |
数据三副本存储,利用率低,成本高 |
hadoop分布式文件系统(hdfs)使用三副本保存数据,磁盘空间利用率仅33%,单盘利用率低于70%。 |
方案架构
针对传统企业在大数据场景面临的问题,华为云提供了基于对象存储服务obs作为统一数据湖存储的大数据存算分离方案。
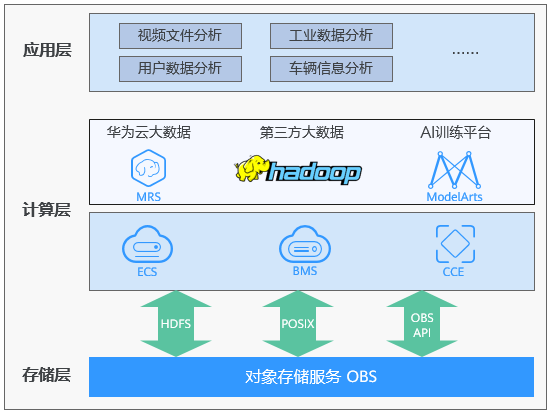
华为云大数据存算分离方案基于对象存储服务obs的大容量高带宽能力,以及多协议共享访问技术(hdfs/posix/obs api),实现hadoop生态多计算引擎(hive、spark等)兼容对接。
方案优势
相比传统企业在本地idc机房部署大数据业务,华为云数据存算分离方案的主要优势如表2。
|
序号 |
主要优势 |
详细描述 |
|---|---|---|
|
1 |
融合高效,协同分析 |
|
|
2 |
存算分离,资源利用率高 |
计算存储解耦,支持独立扩容或缩容,计算资源可弹性伸缩,资源利用率提升。 |
|
3 |
数据ec冗余存储,利用率高,成本低 |
对象存储服务obs支持利用率最高的分布式数据容错技术erasure code,磁盘利用率大幅提升,数据存储空间需求远低于三副本。 |
此外,对象存储服务obs提供了,可与上层大数据平台无缝对接,实现业务零改造。
obsfilesystem的主要作用:提供hdfs文件系统的相关接口实现,让大数据计算引擎(hive、spark等)可以将obs作为hdfs协议的底层存储。
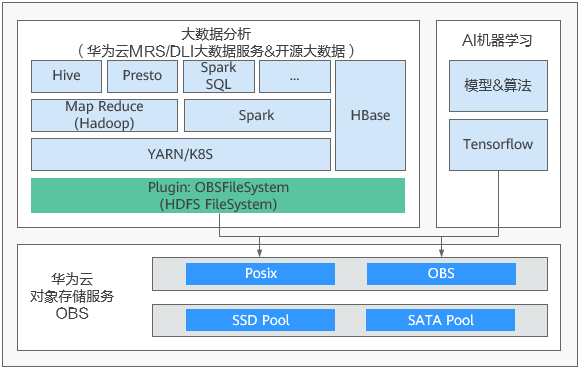

obs九游平台的服务支持对象存储桶(对象语义)和并行文件系统(posix文件语义),在大数据场景下建议选择并行文件系统。并行文件系统支持posix文件语义,通过obsfilesystem封装,相较对象语义增加rename、append、hflush/hsync接口,实现完善的hdfs语义,为大数据计算提供了更好的性能。
基于上述优势,华为云存算分离大数据方案相比传统大数据方案,在同样的业务规模下所使用的计算资源、存储资源以及服务器数量都会有明显下降,同时资源利用率也能得到显著提升,可帮助企业降低业务综合成本。
文档使用范围
本最佳实践主要提供华为云大数据存算分离方案中不同大数据平台和大数据组件与对象存储服务obs的对接指导,以及hdfs数据迁移至对象存储服务obs的方案。
相关文档
意见反馈
文档内容是否对您有帮助?
如您有其它疑问,您也可以通过华为云社区问答频道来与我们联系探讨




