gpu服务器上配置lite server资源软件环境-九游平台
场景描述
本文旨在指导如何在gpu裸金属服务器上,安装nvidia、cuda驱动等环境配置。由于不同gpu预置镜像中预安装的软件不同,您通过lite server算力资源和镜像版本配套关系章节查看已安装的软件。下面为常见的软件安装步骤,您可针对需要安装的软件查看对应的内容:
以下提供常见的配置场景,您可查看相关文档方便您快速配置:
安装nvidia驱动
- 打开。
- 以ant8规格为例,根据ant8的详细信息和您所需的cuda版本选择驱动。
图1 驱动选择
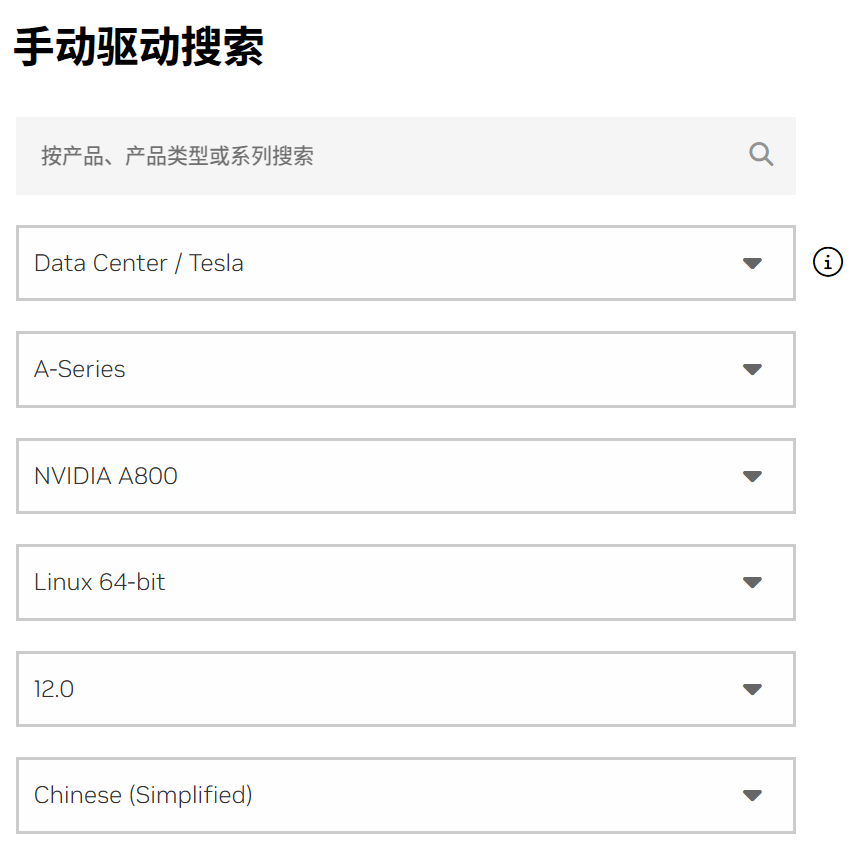 选择后会自动出现driver版本并下载,或者直接。
选择后会自动出现driver版本并下载,或者直接。wget https://cn.download.nvidia.com/tesla/470.182.03/nvidia-linux-x86_64-470.182.03.run
- 添加权限。
chmod x nvidia-linux-x86_64-470.182.03.run
- 运行安装文件。
./nvidia-linux-x86_64-470.182.03.run
至此nvidia-driver驱动安装完成。
安装cuda驱动
上文安装nvidia驱动是根据cuda12.0选择的安装包, 因此下文默认安装cuda 12.0。
- 进入页面。
- 选择operating system、architecture、distribution、version、installer type后,会生成对应的安装命令,复制安装命令并运行即可。
图2 选择版本

对应所得安装命令为:
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-ubuntu2004.pin sudo mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600 wget https://developer.download.nvidia.com/compute/cuda/12.1.1/local_installers/cuda-repo-ubuntu2004-12-1-local_12.1.1-530.30.02-1_amd64.deb sudo dpkg -i cuda-repo-ubuntu2004-12-1-local_12.1.1-530.30.02-1_amd64.deb sudo cp /var/cuda-repo-ubuntu2004-12-1-local/cuda-*-keyring.gpg /usr/share/keyrings/ sudo apt-get update sudo apt-get -y install cuda

如果需要找到历史版本的cuda,您可请单击cuda历史版本的查找所需的cuda版本。
安装docker
部分vnt1裸金属服务器的预置镜像中未安装docker,您可参考以下步骤进行安装。
- 安装docker。
curl https://get.docker.com | sh && sudo systemctl --now enable docker
- 安装nivdia容器插件。
distribution=$(. /etc/os-release;echo $id$version_id) && curl -fssl https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg && curl -s -l https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list apt-get update apt-get install -y nvidia-container-toolkit nvidia-ctk runtime configure --runtime=docker systemctl restart docker
- 验证docker模式环境是否安装成功。
基于pytorch2.0镜像验证(本案例中镜像较大,拉取时间可能较长)。
docker run -ti --runtime=nvidia --gpus all pytorch/pytorch:2.0.0-cuda11.7-cudnn8-devel bash
图3 成功拉取镜像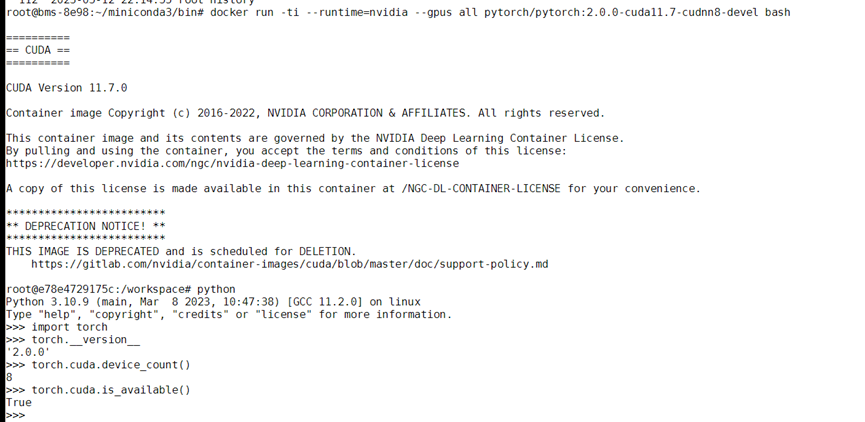
安装nvidia-fabricmanager
ant系列gpu支持nvlink & nvswitch,如果您使用多gpu卡的机型,需额外安装与驱动版本对应的nvidia-fabricmanager服务使gpu卡间能够互联,否则可能无法正常使用gpu实例。
nvidia-fabricmanager必须和nvidia driver版本保持一致。
以安装515.105.01版本为例。
version=515.105.01
main_version=$(echo $version | awk -f '.' '{print $1}')
apt-get update
apt-get -y install nvidia-fabricmanager-${main_version}=${version}-*
验证驱动安装结果:启动fabricmanager服务并查看状态是否为“running”。
nvidia-smi -pm 1 nvidia-smi systemctl enable nvidia-fabricmanager systemctl start nvidia-fabricmanager systemctl status nvidia-fabricmanager
gp vnt1裸金属服务器euleros 2.9安装nvidia 515 cuda 11.7
本小节旨在指导如何在gp vnt1裸金属服务器上(euler2.9系统),安装nvidia驱动版本515.105.01,cuda版本11.7.1。
- 安装nvidia驱动。
wget https://us.download.nvidia.com/tesla/515.105.01/nvidia-linux-x86_64-515.105.01.run chmod 700 nvidia-linux-x86_64-515.105.01.run yum install -y elfutils-libelf-devel ./nvidia-linux-x86_64-515.105.01.run --kernel-source-path=/usr/src/kernels/4.18.0-147.5.1.6.h998.eulerosv2r9.x86_64
默认情况下vnt1裸金属服务器在euleros 2.9使用的yum源是“http://repo.huaweicloud.com”,该源可用。如果执行“yum update”时报错, 显示有软件包冲突等问题, 可通过“yum remove xxx软件包”解决该问题。
nvidia的驱动程序是一个二进制文件,需使用系统中的libelf库(在elfutils-libelf-devel开发包)中。它提供了一组c函数,用于读取、修改和创建elf文件,而nvidia驱动程序需要使用这些函数来解析当前正在运行的内核和其他相关信息。
安装过程中的提示均选ok或yes,安装好后执行reboot重启机器,再次登录后执行命令查看gpu卡信息。
nvidia-smi -pm 1 #该命令执行时间较长,请耐心等待,作用为启用持久模式,可以优化linux实例上gpu设备的性能 nvidia-smi
- 安装cuda。
wget https://developer.download.nvidia.com/compute/cuda/11.7.1/local_installers/cuda_11.7.1_515.65.01_linux.run chmod 700 cuda_11.7.1_515.65.01_linux.run ./cuda_11.7.1_515.65.01_linux.run --toolkit --samples --silent
安装好后执行以下命令检查安装结果:
/usr/local/cuda/bin/nvcc -v
- pytorch2.0安装和cuda验证指南。
pytorch2.0所需环境为python3.10, 安装配置miniconda环境。
- miniconda安装并创建alpha环境。
wget https://repo.anaconda.com/miniconda/miniconda3-py310_23.1.0-1-linux-x86_64.sh chmod 750 miniconda3-py310_23.1.0-1-linux-x86_64.sh bash miniconda3-py310_23.1.0-1-linux-x86_64.sh -b -p /home/miniconda export path=/home/miniconda/bin:$path conda create --quiet --yes -n alpha python=3.10
- 安装pytorch2.0并验证cuda状态。
在alpha环境下安装torch2.0,使用清华pip源完成。
source activate alpha pip install torch==2.0 -i https://pypi.tuna.tsinghua.edu.cn/simple python
验证torch与cuda的安装状态,输出为true即为正常。import torch print(torch.cuda.is_available())
- miniconda安装并创建alpha环境。
gp vnt1裸金属服务器ubuntu 18.04安装nvidia 470 cuda 11.4
本小节旨在指导如何在gp vnt1裸金属服务器上(ubuntu 18.04系统),安装nvidia驱动版本470,cuda版本11.4。
- 安装nvidia驱动。
apt-get update sudo apt-get install nvidia-driver-470
- 安装cuda。
wget https://developer.download.nvidia.com/compute/cuda/11.4.4/local_installers/cuda_11.4.4_470.82.01_linux.run chmod x cuda_11.4.4_470.82.01_linux.run ./cuda_11.4.4_470.82.01_linux.run --toolkit --samples --silent
- 验证nvidia安装结果。
nvidia-smi -pm 1 nvidia-smi /usr/local/cuda/bin/nvcc -v
- 安装pytorch2.0和验证cuda验证。
pytorch2.0所需环境为python3.10, 安装配置miniconda环境。
- miniconda安装并创建alpha环境。
wget https://repo.anaconda.com/miniconda/miniconda3-py310_23.1.0-1-linux-x86_64.sh chmod 750 miniconda3-py310_23.1.0-1-linux-x86_64.sh bash miniconda3-py310_23.1.0-1-linux-x86_64.sh -b -p /home/miniconda export path=/home/miniconda/bin:$path conda create --quiet --yes -n alpha python=3.10
- 安装pytorch2.0并验证cuda状态。
在alpha环境下安装torch2.0,使用清华pip源完成。
source activate alpha conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia python
验证torch与cuda的安装状态,输出为true即为正常。import torch print(torch.cuda.is_available())
- miniconda安装并创建alpha环境。
gp vnt1裸金属服务器ubuntu18.04安装nvidia 515 cuda 11.7
本小节旨在指导如何在gp vnt1裸金属服务器上(ubuntu 18.04系统),安装nvidia驱动版本515、cuda版本11.7和docker。
- nvidia驱动安装。
wget https://us.download.nvidia.com/tesla/515.105.01/nvidia-linux-x86_64-515.105.01.run chmod x nvidia-linux-x86_64-515.105.01.run ./nvidia-linux-x86_64-515.105.01.run
- cuda安装。
wget https://developer.download.nvidia.com/compute/cuda/11.7.1/local_installers/cuda_11.7.1_515.65.01_linux.run chmod x cuda_11.7.1_515.65.01_linux.run ./cuda_11.7.1_515.65.01_linux.run --toolkit --samples –silent
- 安装docker。
curl https://get.docker.com | sh && sudo systemctl --now enable docker
- 安装nivdia容器插件。
distribution=$(. /etc/os-release;echo $id$version_id) && curl -fssl https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg && curl -s -l https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list apt-get update apt-get install -y nvidia-container-toolkit nvidia-ctk runtime configure --runtime=docker systemctl restart docker
- 验证docker模式环境是否安装成功。
基于pytorch2.0镜像验证(本案例中镜像较大,拉取时间可能较长)。
docker run -ti --runtime=nvidia --gpus all pytorch/pytorch:2.0.0-cuda11.7-cudnn8-devel bash
图4 成功拉取镜像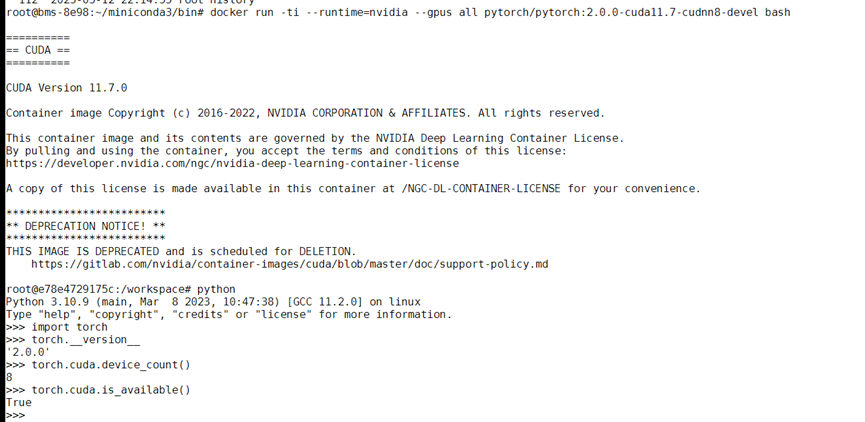
gp ant8裸金属服务器ubuntu 20.04安装nvidia 515 cuda 11.7
本小节旨在指导如何在gp ant8裸金属服务器上(ubuntu 20.04系统),安装nvidia驱动版本515、cuda版本11.7、nvidia-fabricmanager版本515,并进行nccl-test测试。
- 替换apt源。
sudo sed -i "s@http://.*archive.ubuntu.com@http://repo.huaweicloud.com@g" /etc/apt/sources.list sudo sed -i "s@http://.*security.ubuntu.com@http://repo.huaweicloud.com@g" /etc/apt/sources.list sudo apt update
- 安装nvidia驱动。
wget https://us.download.nvidia.com/tesla/515.105.01/nvidia-linux-x86_64-515.105.01.run chmod x nvidia-linux-x86_64-515.105.01.run ./nvidia-linux-x86_64-515.105.01.run
- 安装cuda。
# run包安装 wget https://developer.download.nvidia.com/compute/cuda/11.7.0/local_installers/cuda_11.7.0_515.43.04_linux.run chmod x cuda_11.7.0_515.43.04_linux.run ./cuda_11.7.0_515.43.04_linux.run --toolkit --samples --silent
- 安装nccl。
- nccl安装可参考。
- nccl和cuda版本的配套关系和安装方法参考。
本文使用cuda版本是11.7,因此安装nccl的命令为:
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-keyring_1.0-1_all.deb sudo dpkg -i cuda-keyring_1.0-1_all.deb sudo apt update sudo apt install libnccl2=2.14.3-1 cuda11.7 libnccl-dev=2.14.3-1 cuda11.7
安装完成后可以查看:
图5 查看nccl
- 安装nvidia-fabricmanager。
nvidia-fabricmanager必须和nvidia driver版本保持一致。
version=515.105.01 main_version=$(echo $version | awk -f '.' '{print $1}') apt-get update apt-get -y install nvidia-fabricmanager-${main_version}=${version}-*验证驱动安装结果:启动fabricmanager服务并查看状态是否为“running”。
nvidia-smi -pm 1 nvidia-smi systemctl enable nvidia-fabricmanager systemctl start nvidia-fabricmanager systemctl status nvidia-fabricmanager
- 安装nv-peer-memory。
git clone https://github.com/mellanox/nv_peer_memory.git cd ./nv_peer_memory ./build_module.sh cd /tmp tar xzf /tmp/nvidia-peer-memory_1.3.orig.tar.gz cd nvidia-peer-memory-1.3 dpkg-buildpackage -us -uc dpkg -i ../nvidia-peer-memory-dkms_1.2-0_all.deb
nv_peer_mem工作在linux内核态,安装完成后需要看是否加载到内核,通过执行“lsmod | grep peer”查看是否加载。
- 如果git clone拉不下来代码,可能需要先设置下git的配置:
git config --global core.compression -1 export git_ssl_no_verify=1 git config --global http.sslverify false git config --global http.postbuffer 10524288000 git config --global http.lowspeedlimit 1000 git config --global http.lowspeedtime 1800
- 如果安装完成后lsmod看不到nv-peer-memory,可能是由于ib驱动版本过低导致,此时需要升级ib驱动,升级命令:
wget https://content.mellanox.com/ofed/mlnx_ofed-5.4-3.6.8.1/mlnx_ofed_linux-5.4-3.6.8.1-ubuntu20.04-x86_64.tgz tar -zxvf mlnx_ofed_linux-5.4-3.6.8.1-ubuntu20.04-x86_64.tgz cd mlnx_ofed_linux-5.4-3.6.8.1-ubuntu20.04-x86_64 apt-get install -y python3 gcc quilt build-essential bzip2 dh-python pkg-config dh-autoreconf python3-distutils debhelper make ./mlnxofedinstall --add-kernel-support
- 如果想安装其它更高版本的ib驱动,请参考。比如要安装mlnx_ofed-5.8-2.0.3.0 (当前最新版本),则命令为:
wget https://content.mellanox.com/ofed/mlnx_ofed-5.8-2.0.3.0/mlnx_ofed_linux-5.8-2.0.3.0-ubuntu20.04-x86_64.tgz tar -zxvf mlnx_ofed_linux-5.8-2.0.3.0-ubuntu20.04-x86_64.tgz cd mlnx_ofed_linux-5.8-2.0.3.0-ubuntu20.04-x86_64 apt-get install -y python3 gcc quilt build-essential bzip2 dh-python pkg-config dh-autoreconf python3-distutils debhelper make ./mlnxofedinstall --add-kernel-support
- 安装完nv_peer_mem, 如果想查看其状态可以输入如下指令:
/etc/init.d/nv_peer_mem/ status
如果发现没有此文件,则可能安装的时候没有默认复制过来,需要复制即可:
cp /tmp/nvidia-peer-memory-1.3/nv_peer_mem.conf /etc/infiniband/ cp /tmp/nvidia-peer-memory-1.3/debian/tmp/etc/init.d/nv_peer_mem /etc/init.d/
- 如果git clone拉不下来代码,可能需要先设置下git的配置:
- 设置环境变量。
mpi路径版本需要匹配,可以通过“ls /usr/mpi/gcc/”查看openmpi的具体版本。
# 加入到~/.bashrc export ld_library_path=/usr/local/cuda/lib:usr/local/cuda/lib64:/usr/include/nccl.h:/usr/mpi/gcc/openmpi-4.1.2a1/lib:$ld_library_path export path=$path:/usr/local/cuda/bin:/usr/mpi/gcc/openmpi-4.1.2a1/bin
- 安装编译nccl-test。
cd /root git clone https://github.com/nvidia/nccl-tests.git cd ./nccl-tests make mpi=1 mpi_home=/usr/mpi/gcc/openmpi-4.1.2a1 -j 8
编译时需要加上mpi=1的参数,否则无法进行多机之间的测试。
mpi路径版本需要匹配,可以通过“ls /usr/mpi/gcc/”查看openmpi的具体版本。
- nccl-test测试。
- 单机测试:
/root/nccl-tests/build/all_reduce_perf -b 8 -e 1024m -f 2 -g 8
- 多机测试(btl_tcp_if_include后面替换为主网卡名称):
mpirun --allow-run-as-root --hostfile hostfile -mca btl_tcp_if_include eth0 -mca btl_openib_allow_ib true -x nccl_debug=info -x nccl_ib_gid_index=3 -x nccl_ib_tc=128 -x nccl_algo=ring -x nccl_ib_hca=^mlx5_bond_0 -x ld_library_path /root/nccl-tests/build/all_reduce_perf -b 8 -e 11g -f 2 -g 8
hostfile格式:
#主机私有ip 单节点进程数 192.168.20.1 slots=1 192.168.20.2 slots=1
nccl环境变量说明:
- nccl_ib_gid_index=3 :数据包走交换机的队列4通道,这是roce协议标准。
- nccl_ib_tc=128 :使用roce v2协议,默认使用roce v1,但是v1在交换机上没有拥塞控制,可能会丢包,而且后续的交换机不会支持v1,会导致无法运行。
- nccl_algo=ring :nccl_test的总线bandwidth是在假定是ring算法的情况下计算出来的。
计算公式是有假设的: 总线带宽 = 算法带宽 * 2 ( n-1 ) / n ,算法带宽 = 数据量 / 时间
但是这个计算公式的前提是用ring算法,tree算法的总线带宽不可以这么计算。
如果tree算法算出来的总线带宽相当于是相对ring算法的性能加速。算法计算总耗时减少了,所以用公式算出来的总线带宽也增加了。理论上tree算法是比ring算法更优的,但是tree算法对网络的要求比ring高,计算可能不太稳定。 tree算法可以用更少的数据通信量完成all reduce计算,但用来测试性能不太合适。因此,会出现两节点实际带宽100,但测试出速度110,甚至130gb/s的情况。加这个参数以后,2节点和2节点以上情况的速度才会稳定一些。
测试时需要执行mpirun的节点到hostfile中的节点间有免密登录,设置ssh免密登录方法如下:- 客户端生成公私钥。
执行如下命令,在本地客户端生成公私钥(一路回车默认即可)。
ssh-keygen
上面这个命令会在用户目录.ssh文件夹下创建“id_rsa.pub”(公钥)和“id_rsa”(私钥),可通过如下命令查看:
cd ~/.ssh
- 上传公钥到服务器。
例如用户名为root,服务器地址为192.168.222.213,则将公钥上传至服务器的命令如下:
ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.222.213
通过如下命令可以看到客户端写入到服务器的id_rsa.pub (公钥)内容:
cd ~/.ssh vim authorized_keys
- 测试免密登录。
客户端通过ssh连接远程服务器,即可免密登录。
ssh root@192.168.222.213
- 客户端生成公私钥。
- 单机测试:
相关文档
意见反馈
文档内容是否对您有帮助?
如您有其它疑问,您也可以通过华为云社区问答频道来与我们联系探讨




