open-九游平台
本文档主要介绍如何在modelarts lite server上,使用pytorch_npu 华为自研ascend snt9b硬件,完成open-sora训练和推理。
资源规格要求
推荐使用“西南-贵阳一”region上的lite server资源和ascend snt9b。训练至少需要单机8卡,推理需要单机单卡。
|
名称 |
版本 |
|---|---|
|
cann |
cann_8.0.rc2 |
|
pytorch |
pytorch_2.1.0 |
获取软件和镜像
|
分类 |
名称 |
获取路径 |
|---|---|---|
|
插件代码包 |
ascendcloud-3rdaigc-6.3.905-xxx.zip 文件名中的xxx表示具体的时间戳,以包名的实际时间为准。 |
获取路径: 如果没有软件下载权限,请联系您所在企业的华为方九游平台的技术支持下载获取。 |
|
基础镜像包 |
swr.cn-southwest-2.myhuaweicloud.com/atelier/pytorch_2_1_ascend:pytorch_2.1.0-cann_8.0.rc2-py_3.9-hce_2.0.2312-aarch64-snt9b-20240528150158-b521cc0 |
swr上拉取 |
约束限制
- 本文档适配昇腾云modelarts 6.3.905版本,请参考表2获取配套版本的软件包和镜像,请严格遵照版本配套关系使用本文档。
- 本文档适配的是
- 训练至少需要单机8卡,推理需要单机单卡。
- 确保容器可以访问公网。
step1 检查环境
- 请参考,购买lite server资源,并确保机器已开通,密码已获取,能通过ssh登录,不同机器之间网络互通。

购买lite server资源时如果无可选资源规格,需要联系华为云九游平台的技术支持申请开通。
当容器需要提供服务给多个用户,或者多个用户共享使用该容器时,应限制容器访问openstack的管理地址(169.254.169.254),以防止容器获取宿主机的元数据。具体操作请参见。
- ssh登录机器后,检查npu卡状态。运行如下命令,返回npu设备信息。
npu-smi info # 在每个实例节点上运行此命令可以看到npu卡状态 npu-smi info -l | grep total # 在每个实例节点上运行此命令可以看到总卡数
如出现错误,可能是机器上的npu设备没有正常安装,或者npu镜像被其他容器挂载。请先正常安装固件和驱动,或释放被挂载的npu。
- 检查是否安装docker。
docker -v #检查docker是否安装
如尚未安装,运行以下命令安装docker。
yum install -y docker-engine.aarch64 docker-engine-selinux.noarch docker-runc.aarch64
- 配置ip转发,用于容器内的网络访问。执行以下命令查看net.ipv4.ip_forward配置项的值,如果为1,可跳过此步骤。
sysctl -p | grep net.ipv4.ip_forward
如果net.ipv4.ip_forward配置项的值不为1,执行以下命令配置ip转发。sed -i 's/net\.ipv4\.ip_forward=0/net\.ipv4\.ip_forward=1/g' /etc/sysctl.conf sysctl -p | grep net.ipv4.ip_forward
step2 启动镜像
- 获取基础镜像。建议使用官方提供的镜像。镜像地址{image_url}参见表2。
docker pull {image_url} - 启动容器镜像。启动前请先按照参数说明修改${}中的参数。可以根据实际需要增加修改参数。训练至少需要单机8卡,推理需要单机单卡。
export work_dir="自定义挂载的工作目录" export container_work_dir="自定义挂载到容器内的工作目录" export container_name="自定义容器名称" export image_name="镜像名称" // 启动一个容器去运行镜像 docker run -itd \ --device=/dev/davinci0 \ --device=/dev/davinci1 \ --device=/dev/davinci2 \ --device=/dev/davinci3 \ --device=/dev/davinci4 \ --device=/dev/davinci5 \ --device=/dev/davinci6 \ --device=/dev/davinci7 \ --device=/dev/davinci_manager \ --device=/dev/devmm_svm \ --device=/dev/hisi_hdc \ -v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \ -v /usr/local/dcmi:/usr/local/dcmi \ -v /etc/ascend_install.info:/etc/ascend_install.info \ -v /sys/fs/cgroup:/sys/fs/cgroup:ro \ -v /usr/local/ascend/driver:/usr/local/ascend/driver \ --shm-size 80g \ --net=bridge \ -v ${work_dir}:${container_work_dir} \ --name ${container_name} \ ${image_name} bash参数说明:
- device=/dev/davinci0,..., --device=/dev/davinci7:挂载npu设备,示例中挂载了8张卡davinci0~davinci7。
- ${work_dir}:${container_work_dir} 代表需要在容器中挂载宿主机的目录。宿主机和容器使用不同的大文件系统,work_dir为宿主机中工作目录,目录下存放着训练所需代码、数据等文件。container_dir为要挂载到的容器中的目录。为方便两个地址可以相同。
- shm-size:共享内存大小,建议不低于80gb。
- name ${container_name}:容器名称,进入容器时会用到,此处可以自己定义一个容器名称。
- v ${work_dir}:${container_work_dir}:代表需要在容器中挂载宿主机的目录。宿主机和容器使用不同的文件系统。work_dir为宿主机中工作目录,目录下存放着训练所需代码、数据等文件。container_work_dir为要挂载到的容器中的目录。为方便两个地址可以相同。
- ${image_name}:代表镜像地址。
- 容器不能挂载到/home/ma-user目录,此目录为ma-user用户家目录。如果容器挂载到/home/ma-user下,拉起容器时会与基础镜像冲突,导致基础镜像不可用。
- driver及npu-smi需同时挂载至容器。
- 不要将多个容器绑到同一个npu上,会导致后续的容器无法正常使用npu功能。
- 进入容器。需要将${container_name}替换为实际的容器名称。
docker exec -it ${container_name} bash
启动容器默认使用ma-user用户。后续所有命令执行也建议使用ma-user用户。
step3 获取代码包并安装依赖
- 下载插件代码包ascendcloud-3rdaigc-6.3.905-xxx.zip文件,上传到容器的/home/ma-user/目录下,解压并安装相关依赖。获取路径参见获取软件和镜像。
mkdir -p /home/ma-user/ascendcloud-aigc-algorithm-open_sora #创建目录 cd /home/ma-user/ascendcloud-aigc-algorithm-open_sora/ #进入目录 unzip -zxvf ascendcloud-3rdaigc-6.3.905-*.zip tar -zxvf ascendcloud-aigc-algorithm-open_sora.tar.gz rm -rf ascendcloud-3rdaigc-6.3.905-*
- 安装python环境。
pip install -r requirements.txt cp attention_processor.py /home/ma-user/anaconda3/envs/pytorch-2.1.0/lib/python3.9/site-packages/diffusers/models/attention_processor.py cp low_level_optim.py /home/ma-user/anaconda3/envs/pytorch-2.1.0/lib/python3.9/site-packages/colossalai/zero/low_level/low_level_optim.py
step4 下载数据集
训练使用的开源数据集ucf101.rar,执行如下命令下载数据集并处理。数据集相关介绍参见。
mkdir datasets cd datasets wget https://www.crcv.ucf.edu/data/ucf101/ucf101.rar unrar x ucf101.rar cd .. python -m tools.datasets.convert_dataset ucf101 ./datasets/ --split ucf-101 mv ucf101_ucf-101.csv datasets/
处理完数据集后的结果如图1所示。

step5 启动训练服务
训练至少需要单机8卡。建议手动下载所需的权重文件,放在weights文件夹下。在/home/ma-user/ascendcloud-aigc-algorithm-open_sora/目录下进行操作。
- 创建weights文件夹。
mkdir weights
- 下载基础模型权重:pixart-xl-2-512x512.pth和pixart-xl-2-256x256.pth
cd weights # 下载pixart-xl-2-512x512.pth和pixart-xl-2-256x256.pth wget https://huggingface.co/pixart-alpha/pixart-alpha/resolve/main/pixart-xl-2-512x512.pth wget https://huggingface.co/pixart-alpha/pixart-alpha/resolve/main/pixart-xl-2-256x256.pth
- 下载vae权重:sd-vae-ft-ema
在weights文件夹下创建sd-vae-ft-ema文件夹。
mkdir sd-vae-ft-ema
然后进入九游平台官网地址: ,手动下载如图2所示四个文件,并上传到服务器的/home/ma-user/ascendcloud-aigc-algorithm-open_sora/weights/sd-vae-ft-ema/目录下。
图2 huggingface中sd-vae-ft-ema模型目录内容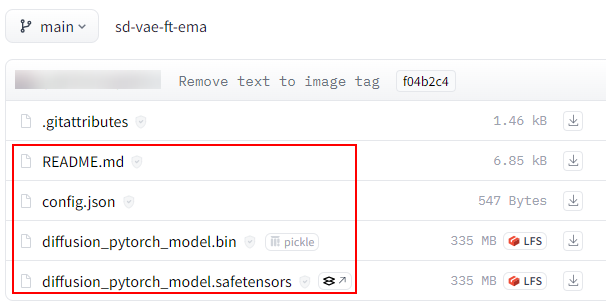
上传完成后,weights/sd-vae-ft-ema/目录内容如图3所示。
图3 服务器 weights/sd-vae-ft-ema/目录内容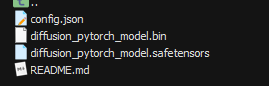
- 下载encoder模型权重:deepfloyd/t5-v1_1-xxl
在weights文件夹下创建t5-v1_1-xxl文件夹。
mkdir t5-v1_1-xxl
然后进入九游平台官网地址 ,手动下载如图4所示文件,并放到 /home/ma-user/ascendcloud-aigc-algorithm-open_sora/weights/t5-v1_1-xxl 文件夹下。
图4 huggingface中t5-v1_1-xxl模型目录内容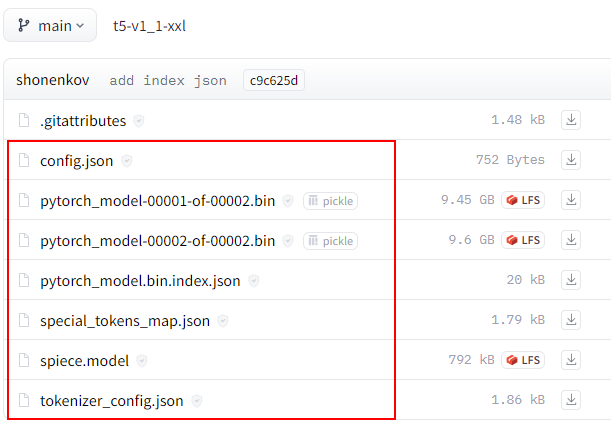
上传完成后,weights/t5-v1_1-xxl/目录下内容如图5所示。
图5 服务器 weights/t5-v1_1-xxl/目录内容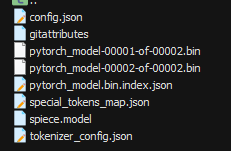
最后weights文件夹下内容目录如图6所示。
图6 服务器weights目录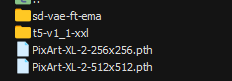
从weights目录下返回到代码目录下。
cd ..
- 在/home/ma-user/ascendcloud-aigc-algorithm-open_sora/目录下执行如下命令启动训练脚本。
torchrun --nnodes=1 --nproc_per_node=8 train.py configs/opensora/train/64x512x512.py
正常训练过程如下图所示。训练完成后,关注loss值,loss曲线收敛,记录总耗时和单步耗时。训练过程中,训练日志会在最后的rank节点打印。可以使用可视化工具查看loss收敛情况。
图7 正常训练过程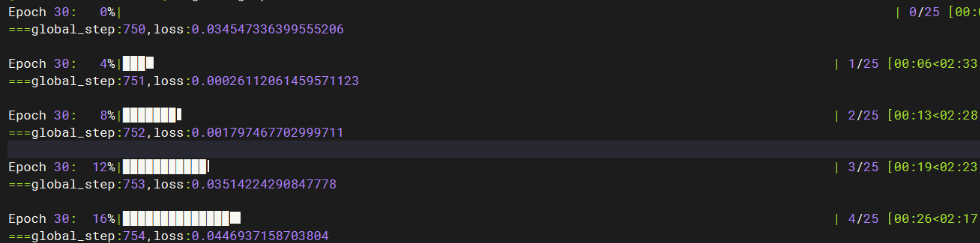
训练完成后权重保存在自动生成的目录,例如:outputs/010-f16s3-stdit-xl-2/epoch1-global_step2000/。
图8 训练完成后权重保存信息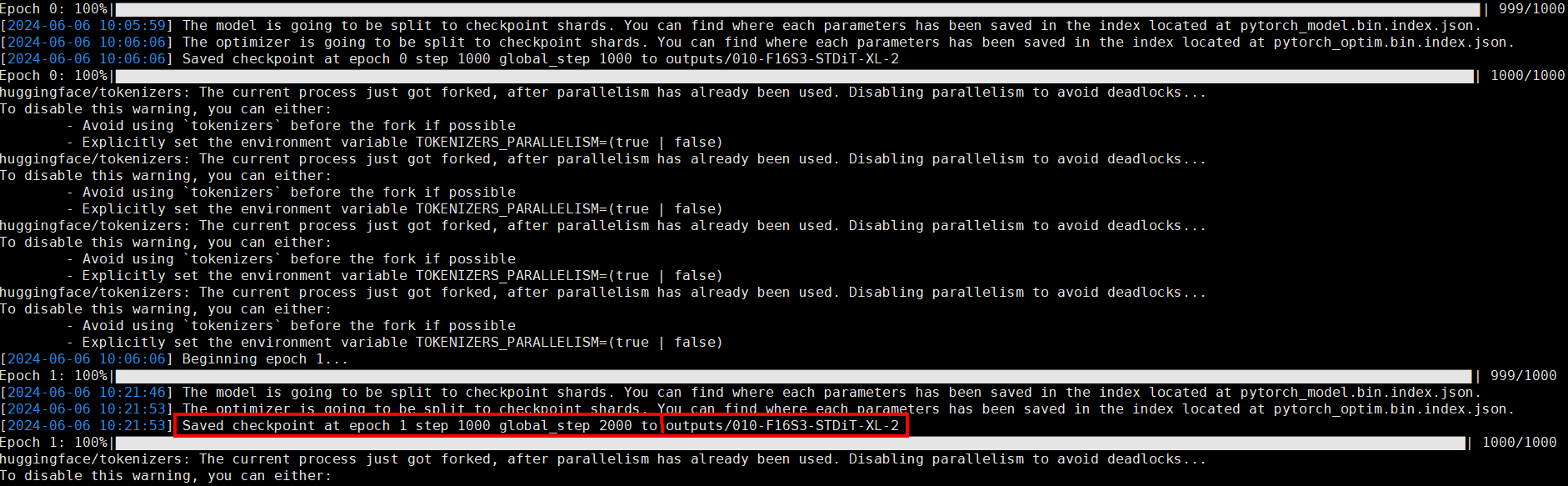
step6 推理
执行如下命令使用官方权重推理。推理脚本inference.py 会自动下载官方权重文件。
torchrun --standalone --nproc_per_node 1 inference.py configs/opensora/inference/64x512x512_npu.py --ckpt-path ./opensora-v1-hq-16x512x512.pth
如果自动下载官方权重文件opensora-v1-hq-16x512x512.pth失败,建议手动下载权重文件并上传到容器/home/ma-user/ascendcloud-aigc-algorithm-open_sora/目录中。
"opensora-v1-hq-16x512x512.pth": ""
执行如下命令使用训练后生成的权重推理。训练完成后会在工作目录/home/ma-user/ascendcloud-aigc-algorithm-open_sora/下自动生成一个outputs文件夹,训练后生成的权重文件存放在outputs文件夹中,例如outputs/010-f16s3-stdit-xl-2/epoch1-global_step2000/。
export ckpt_path=./outputs/.../ #由训练日志中获得 torchrun --standalone --nproc_per_node 1 inference.py configs/opensora/inference/64x512x512_npu.py --ckpt-path $ckpt_path
如果要使用自己的prompt进行推理,可以修改用户自己推理脚本配置文件中prompt_path。例如在configs/opensora/inference/64x512x512.py配置文件中,使用了自己的prompt文件overfit.txt。
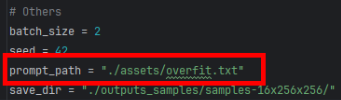
step7 精度对比
由于npu和gpu生成的随机数不一样,需要固定二者的随机数再进行精度对比。通常的做法是先用gpu单卡跑一遍训练,生成固定下来的随机数。然后npu和gpu都用固定的随机数进行单机8卡训练,比较精度。
- 训练精度对齐。对齐前2000步的loss,观察loss在极小误差范围内。
gpu环境下,使用github中的官方代码跑训练任务。github中的官方代码下载路径:
在npu代码 configs/opensora/train/64x512x512.py中把 epochs = 200000 临时改成 epochs = 2000
图10 配置文件64x512x512.py 修改训练步数
将npu代码中configs/opensora/train/64x512x512.py文件和configs/opensora/inference/64x512x512.py文件复制到gpu代码目录中,使用相同的参数配置文件。
将npu代码目录中的opensora/schedulers/iddpm/__init__.py文件和opensora/schedulers/iddpm/gaussian_diffusion.py文件复制到gpu代码目录中,添加固定随机数功能。
进行gpu单机八卡训练,生成固定训练随机数,随机数会保存在noise文件夹中。
mkdir noise_train #创建文件夹noise_train,用于存放生成的随机数 export lock_rand=true #是否固定随机数 export save_rand=true #是否保存生成的随机数 export noise_path="./noise_train" #将生成的随机数保存在"./noise_train"目录 torchrun --nnodes=1 --nproc_per_node=8 train.py configs/opensora/train/64x512x512.py
正常训练时不需要增加如下命令,只有训练精度对比时需要。
export lock_rand=true #是否固定随机数 export save_rand=true #是否保存生成的随机数 export noise_path="./noise_train" #将生成的随机数保存在"./noise_train"目录
在npu和gpu机器使用上面生成的固定随机数,分别跑一遍单机8卡训练,比较在相应目录下生成的loss.txt文件。在npu训练前,需要将上面gpu单机单卡训练生成的"./noise_train"文件夹移到npu相同目录下。npu和gpu的训练命令相同,如下。
export lock_rand=true export save_rand=false export noise_path="./noise_train" torchrun --nnodes=1 --nproc_per_node=8 train.py configs/opensora/train/64x512x512.py
gpu和npu训练脚本中的参数要保持一致,除了参数dtype。npu环境下,dtype="fp16",gpu环境下,dtype="bf16"。
- 基于npu训练后的权重文件和gpu训练后的权重文件,对比推理精度。推理精度对齐流程和训练精度对齐流程相同,先在gpu固定推理的随机数。
mkdir noise_test1 #创建文件夹noise_test1,用于存放生成的随机数 export lock_rand=true #是否固定随机数 export save_rand=true #是否保存生成的随机数 export noise_path="./noise_test1" #将生成的随机数保存在"./noise_test1"目录 export ckpt_path=./outputs/.../ #由训练日志中获得,例如outputs/010-f16s3-stdit-xl-2/epoch1-global_step2000/ torchrun --standalone --nproc_per_node 1 inference.py configs/opensora/inference/64x512x512_npu.py --ckpt-path $ckpt_path
在npu和gpu机器使用上面生成的固定随机数,分别跑一遍单机单卡推理,比较生成的视频是否一致。在npu推理前,需要将上面gpu单机单卡推理生成的"./noise_test1"文件夹移到npu相同目录下。npu和gpu的推理命令相同,如下。
export lock_rand=true export save_rand=false export noise_path="./noise_test1" export ckpt_path=./outputs/.../ #由训练日志中获得,例如outputs/010-f16s3-stdit-xl-2/epoch1-global_step2000/ torchrun --standalone --nproc_per_node 1 inference.py configs/opensora/inference/64x512x512_npu.py --ckpt-path $ckpt_path
- 基于官方权重文件分别在gpu和npu进行推理,对比推理精度。推理精度对齐流程和训练精度对齐流程相同,先在gpu固定推理的随机数。
mkdir noise_test2 #创建文件夹noise_test2,用于存放生成的随机数 export lock_rand=true #是否固定随机数 export save_rand=true #是否保存生成的随机数 export noise_path="./noise_test2" #将生成的随机数保存在"./noise_test2"目录 torchrun --standalone --nproc_per_node 1 inference.py configs/opensora/inference/64x512x512_npu.py --ckpt-path ./opensora-v1-hq-16x512x512.pth
在npu和gpu机器使用上面生成的固定随机数,分别跑一遍单机单卡推理,比较生成的视频是否一致。在npu推理前,需要将上面gpu单机单卡推理生成的"./noise_test2"文件夹移到npu相同目录下。npu和gpu的推理命令相同,如下。
export lock_rand=true export save_rand=false export noise_path="./noise_test2" torchrun --standalone --nproc_per_node 1 inference.py configs/opensora/inference/64x512x512_npu.py --ckpt-path ./opensora-v1-hq-16x512x512.pth
相关文档
意见反馈
文档内容是否对您有帮助?
如您有其它疑问,您也可以通过华为云社区问答频道来与我们联系探讨




