open-九游平台
本文档主要介绍如何在modelarts lite server上,使用pytorch_npu 华为自研ascend snt9b硬件,完成open-sora-plan1.0训练和推理。
方案概览
本方案目前仅适用于部分企业客户,完成本方案的部署,需要先联系您所在企业的华为方九游平台的技术支持。
适配的cann版本是cann_8.0.rc2。
约束限制
- 本方案目前仅适用于企业客户。
- 本文档适配昇腾云modelarts 6.3.907版本,请参考表1获取配套版本的软件包和镜像,请严格遵照版本配套关系使用本文档。
- 确保容器可以访问公网。
资源规格要求
推荐使用“西南-贵阳一”region上的lite server资源和ascend snt9b。
软件配套版本
|
分类 |
名称 |
获取路径 |
|---|---|---|
|
插件代码包 |
ascendcloud-6.3.907软件包中的ascendcloud-aigc-6.3.907-xxx.zip 文件名中的xxx表示具体的时间戳,以包名发布的实际时间为准。 |
获取路径:
说明:
如果上述软件获取路径打开后未显示相应的软件信息,说明您没有下载权限,请联系您所在企业的华为方九游平台的技术支持下载获取。 |
镜像版本
本教程中用到基础镜像地址和配套版本关系如下表所示,请提前了解。
|
配套软件版本 |
镜像用途 |
镜像地址 |
配套 |
获取方式 |
|---|---|---|---|---|
|
6.3.907版本 |
基础镜像 |
swr.cn-southwest-2.myhuaweicloud.com/atelier/pytorch_2_1_ascend:pytorch_2.1.0-cann_8.0.rc2-py_3.9-hce_2.0.2312-aarch64-snt9b-20240727152329-0f2c29a |
cann_8.0.rc2 pytorch_2.1.0 驱动23.0.6 |
从swr拉取 |

不同软件版本对应的基础镜像地址不同,请严格按照软件版本和镜像配套关系获取基础镜像。
step1 检查环境
- 请参考,购买lite server资源,并确保机器已开通,密码已获取,能通过ssh登录,不同机器之间网络互通。
购买lite server资源时如果无可选资源规格,需要联系华为云九游平台的技术支持申请开通。
当容器需要提供服务给多个用户,或者多个用户共享使用该容器时,应限制容器访问openstack的管理地址(169.254.169.254),以防止容器获取宿主机的元数据。具体操作请参见。
- ssh登录机器后,检查npu卡状态。运行如下命令,返回npu设备信息。
npu-smi info # 在每个实例节点上运行此命令可以看到npu卡状态 npu-smi info -l | grep total # 在每个实例节点上运行此命令可以看到总卡数
如出现错误,可能是机器上的npu设备没有正常安装,或者npu镜像被其他容器挂载。请先正常安装固件和驱动,或释放被挂载的npu。
- 检查是否安装docker。
docker -v #检查docker是否安装
如尚未安装,运行以下命令安装docker。
yum install -y docker-engine.aarch64 docker-engine-selinux.noarch docker-runc.aarch64
- 配置ip转发,用于容器内的网络访问。执行以下命令查看net.ipv4.ip_forward配置项的值,如果为1,可跳过此步骤。
sysctl -p | grep net.ipv4.ip_forward
如果net.ipv4.ip_forward配置项的值不为1,执行以下命令配置ip转发。sed -i 's/net\.ipv4\.ip_forward=0/net\.ipv4\.ip_forward=1/g' /etc/sysctl.conf sysctl -p | grep net.ipv4.ip_forward
step2 下载依赖代码包并上传到宿主机
下载华为侧插件代码包ascendcloud-aigc-6.3.907-xxx.zip文件,获取路径参见表1。本案例使用的是解压到子目录 multimodal_algorithm/opensoraplan1.0/ 目录下的所有文件,将该目录上传到宿主机上。
step3 构建镜像
基于官方提供的基础镜像构建自定义镜像open-sora-plan1.0:1.0。参考如下命令编写dockerfile文件。镜像地址{image_url}请参见表2。
from {image_url}
copy --chown=ma-user:ma-group opensoraplan1.0/* /home/ma-user/open-sora-plan1.0
run cd /home/ma-user/open-sora-plan1.0 && bash prepare.sh
workdir /home/ma-user/open-sora-plan1.0
构建自定义镜像open-sora-plan1.0:1.0。
docker build -t open-sora-plan1.0:1.0 .
step4 启动镜像
docker run -itd --name ${container_name} -v /sys/fs/cgroup:/sys/fs/cgroup:ro -v /etc/localtime:/etc/localtime -v /usr/local/ascend/driver:/usr/local/ascend/driver -v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi --shm-size 60g --device=/dev/davinci_manager --device=/dev/hisi_hdc --device=/dev/devmm_svm --device=/dev/davinci0 --security-opt seccomp=unconfined --network=bridge open-sora-plan1.0:1.0 bash
参数说明:
- --name ${container_name}:容器名称,进入容器时会用到,此处可以自己定义一个容器名称。
- --device=/dev/davinci0:挂载npu设备,该推理示例中挂载了1张卡davinci0。
- driver及npu-smi需同时挂载至容器。
- 不要将多个容器绑到同一个npu上,会导致后续的容器无法正常使用npu功能。
step5 进入容器
docker exec -it ${container_name} bash
step6 安装decord
decord是一个高性能的视频处理库,在昇腾环境中安装需要修改一些源码进行适配。
decord建议安装在 /home/ma-user/lib中。
- 安装x264
mkdir /home/ma-user/lib && cd /home/ma-user/lib # x264 install git clone https://github.com/mirror/x264.git export pkg_config_path=/home/ma-user/lib/lib/pkgconfig cd x264 ./configure --enable-shared --prefix=/home/ma-user/lib/ make make install cd ..
- 安装ffmpeg
# ffmpeg install git clone https://github.com/ffmpeg/ffmpeg.git export tmpdir=../tmp-ffmpeg cd ffmpeg git checkout 78f55457c9be420f4109da45de42a36338d56aca # git checkout release/4.0 ./configure --enable-shared --enable-swscale --enable-gpl --enable-nonfree --enable-pic --prefix=/home/ma-user/lib/ --enable-version3 --enable-postproc --enable-pthreads --enable-static --enable-libx264 make make install cd ..
- 安装decord
- 下载decord代码。
git clone --recursive https://github.com/dmlc/decord cd decord
- 第一处修改
vim src/video/ffmpeg/ffmpeg_common.h
在文件ffmpeg_common.h的23行,添加如下内容
#include
图1 文件ffmpeg_common.h修改前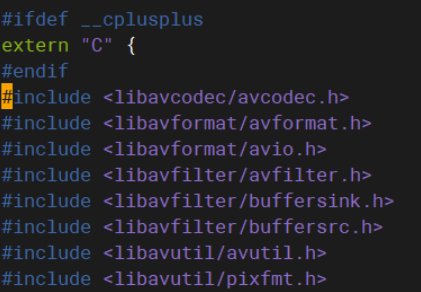 图2 文件ffmpeg_common.h修改后
图2 文件ffmpeg_common.h修改后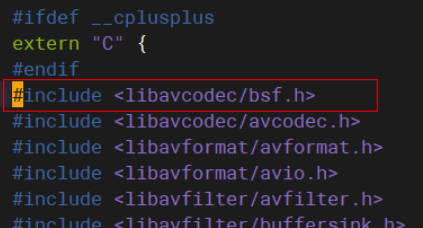
- 第二处修改:
vim src/video/video_reader.cc
在文件video_reader.cc的149行,进行修改:
const avcodec** dec_const = const_cast
(&dec); // int st_nb = av_find_best_stream(fmt_ctx_.get(), avmedia_type_video, stream_nb, -1, &dec, 0); int st_nb = av_find_best_stream(fmt_ctx_.get(), avmedia_type_video, stream_nb, -1, dec_const, 0); 图3 文件video_reader.cc修改前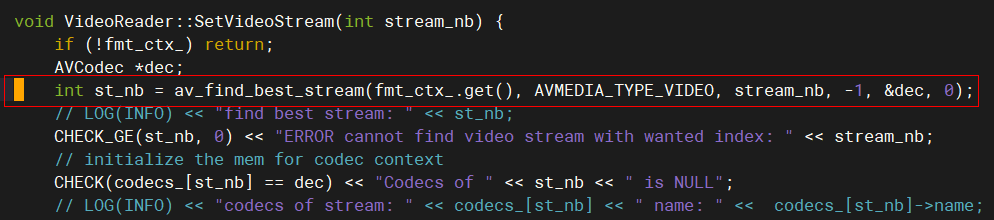 图4 文件video_reader.cc修改后
图4 文件video_reader.cc修改后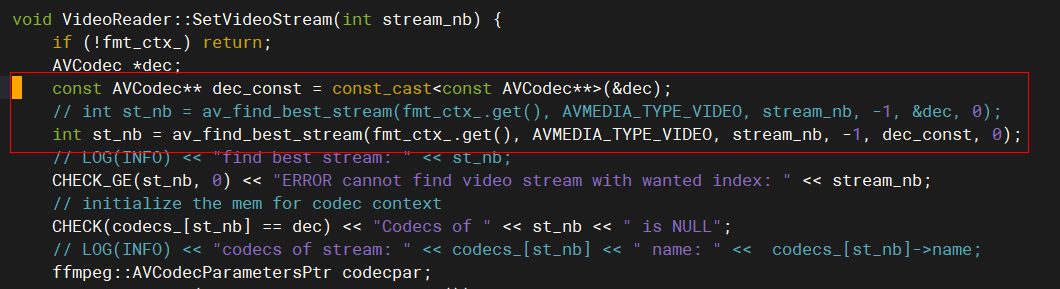
- 执行如下命令编译安装decord。
mkdir build && cd build cmake .. -duse_cuda=0 -dcmake_build_type=release -dffmpeg_dir=/home/ma-user/lib/ make cd ../python python3 setup.py install --user export ld_library_path=$ld_library_path:/home/ma-user/lib/lib echo "export ld_library_path=\$ld_library_path:/home/ma-user/lib/lib" >> ~/.bashrc
- 下载decord代码。
如果重启docker后,环境变量需要重新配置,否则会报错找不到 libavformat.so.60: cannot open shared object file: no such file or directory
配置方式如下:
export ld_library_path=$ld_library_path:/home/ma-user/lib/lib
step7 下载数据集
先创建文件夹用来存放数据集。
mkdir datasets cd datasets
训练使用的开源数据集链接:https://huggingface.co/datasets/languagebind/open-sora-plan-v1.0.0/tree/main。
由于数据集比较大,可以自行选择部分数据集手动下载解压,并放入 ./datasets文件夹下。
例如:这里下载了上述链接中mixkit.tar.gz和sharegpt4v_path_cap_64x512x512.json。
(备注:如果只下载了部分数据集,需要对应修改sharegpt4v_path_cap_64x512x512.json文件)
解压数据集:
tar -xzvf mixkit.tar.gz
解压后的数据集结果如图所示。

step8 下载权重文件
建议手动下载所需的权重文件,在/home/ma-user/open-sora-plan1.0/目录下进行操作。
- 创建文件夹存放不同的权重文件。
mkdir weights mkdir weights_t5 mkdir cache_dir
- 下载基础模型权重t2v.pt放到cache_dir文件夹下。
mkdir latte cd latte git clone -c http.sslverify=false https://huggingface.co/maxin-cn/latte cd latte git reset --hard 83bdc71f7211963153464859d03d46d707e77865
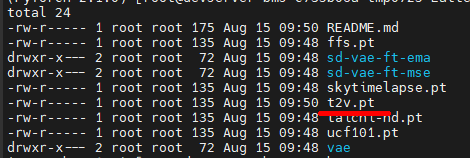
然后将该目录下的t2v.pt文件复制到/home/ma-user/open-sora-plan1.0/cache_dir目录下。
- 下载vae权重vae-ft-mse-840000-ema-pruned.ckpt和配置文件config.json,放在weights文件夹下。
下载链接:https://huggingface.co/stabilityai/sd-vae-ft-ema/tree/main
- 下载text_encoder权重,放在weights_t5文件夹下。
下载链接:,手动下载如图6所示文件,并放到weights_t5文件夹下
图6 huggingface中t5-v1_1-xxl模型目录内容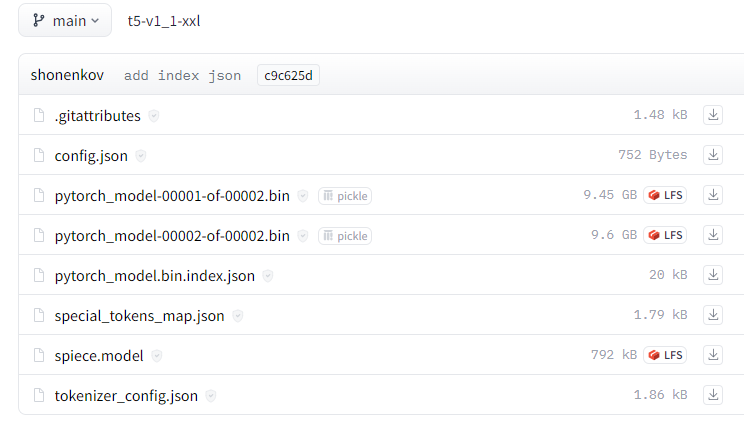
step9 启动训练服务
在/home/ma-user/open-sora-plan1.0/目录下进行操作
训练至少需要单机8卡。
- 命令启动训练脚本。
例如:训练65帧的视频,拼接4张图片,则执行如下命令:
bash train_videoae_65x512x512.sh
正常训练过程如下图所示。训练完成后,关注loss值,loss曲线收敛,记录总耗时和单步耗时。训练过程中,训练日志会在最后的rank节点打印。可以使用可视化工具查看loss收敛情况。
图7 正常训练过程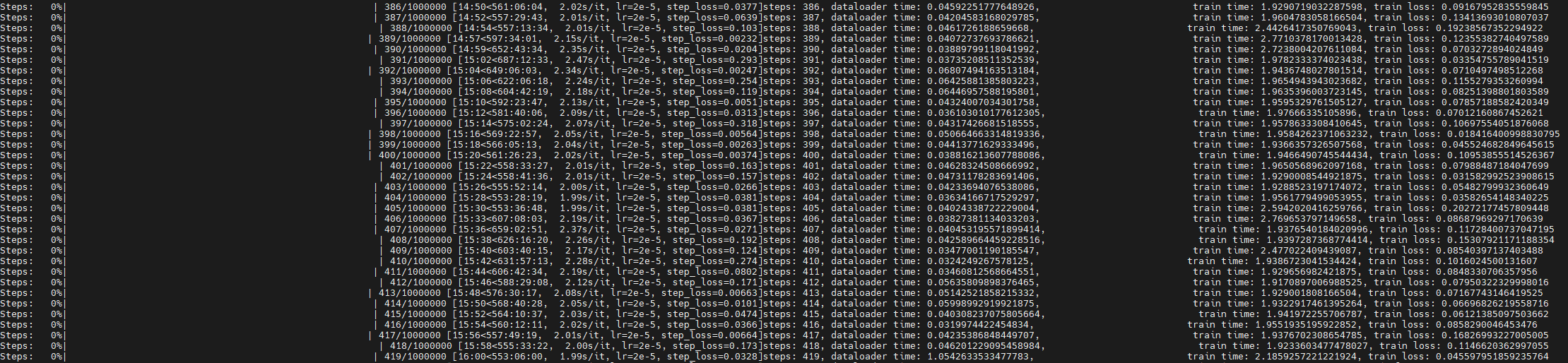
训练完成后权重保存在自动生成的目录,例如:t2v-f17-256-img4-videovae488-bf16-ckpt-xformers-bs4-lr2e-5-t5/epoch1-global_step2000/checkpoint-2000/model。
step10 推理部署
- 使用官方权重文件推理
官方权重下载链接:https://huggingface.co/languagebind/open-sora-plan-v1.0.0/tree/main
创建文件夹存放官方权重文件,
mkdir weights_inference cd weights_inference mkdir vae mkdir 65x512x512
以65x512x512为例:
1,进入链接https://huggingface.co/languagebind/open-sora-plan-v1.0.0/tree/main
2,手动下载65x512x512目录下的权重文件diffusion_pytorch_model.safetensors和配置文件config.json,并放到weights_inference/65x512x512目录下
3,手动下载vae目录下的权重文件diffusion_pytorch_model.safetensors和配置文件config.json,并放到weights_inference/vae目录下。
4,执行如下命令使用官方权重推理。
bash sample_video_65.sh

- 使用训练生成的权重文件推理
在step7 启动训练服务完成后,会在工作目录/home/ma-user/open-sora-plan1.0/下自动生成一个t2v-f17-256-img4-videovae488-bf16-ckpt-xformers-bs4-lr2e-5-t5文件夹,训练后生成的权重文件存放在t2v-f17-256-img4-videovae488-bf16-ckpt-xformers-bs4-lr2e-5-t5文件夹中,例如t2v-f17-256-img4-videovae488-bf16-ckpt-xformers-bs4-lr2e-5-t5/010-f16s3-stdit-xl-2/checkpoint-2000/model。
修改推理配置文件中的权重文件sample_video_65.sh中的路径参数:--model_path,并执行如下推理命令。
bash sample_video_65.sh
相关文档
意见反馈
文档内容是否对您有帮助?
如您有其它疑问,您也可以通过华为云社区问答频道来与我们联系探讨




